聚合价值流分析
本页面提供了关于价值流分析(VSA)聚合后端的高级概述。
当前状态
自GitLab 15.0起,聚合后端在组级别默认使用。
动机
聚合后端的目的是解决VSA功能的性能限制,并为长期发展做好准备。
我们的主数据库未针对分析工作负载进行优化。执行长时间运行的查询可能会影响应用的可靠性。对于大型组,当前的实现(旧后端)速度较慢,在某些情况下,由于配置的语句超时(15秒),甚至无法加载。
旧后端的数据库查询通过IssuableFinders类直接使用核心领域模型:(MergeRequestsFinder 和 IssuesFinder)。随着date range filters请求的变更,从性能角度来看,这种方法已不再可行。
聚合VSA后端的优势:
- 更简单的数据库查询(减少JOIN操作)。
- 更快的聚合速度,仅需访问单个表。
- 可引入更多聚合以提升首屏加载时间。
- 大型组(包含许多子组、项目、问题和合并请求)的性能更好。
- 支持数据库分解。VSA相关的数据库表可独立存放在单独的数据库中,所需开发工作量最小。
- 支持键集分页,这对导出数据很有用。
- 可实现更复杂的事件定义。
- 例如,开始事件可以是两个时间戳列,系统将使用最早的值。
- 示例:
MIN(issues.created_at, issues.updated_at)
示例配置
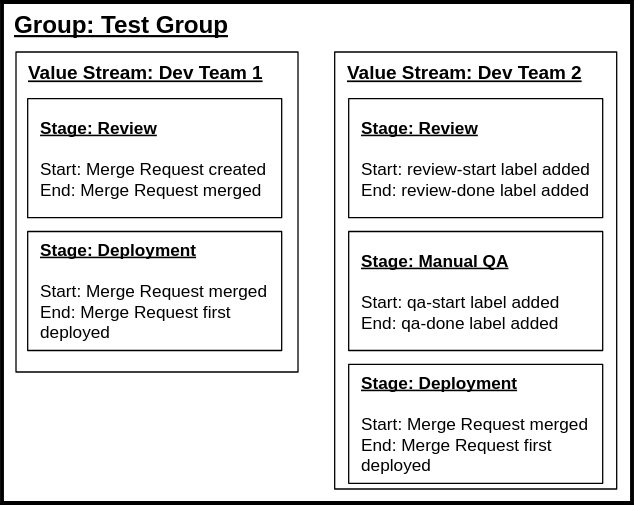
在此示例中,为两个团队设置了两个独立的价值流,这两个团队在使用不同的开发流程的Test Group(顶级命名空间)内。
第一个价值流使用基于标准时间戳的事件来定义阶段。第二个价值流使用标签事件。
示例中的每个价值流和阶段项都会持久化到数据库中。请注意,两个价值流的Deployment阶段相同;这意味着两者的底层stage_event_hash_id相同。stage_event_hash_id减少了后端收集的数据量,并在数据库分区中发挥关键作用。
我们预计价值流和阶段很少会更改。当阶段(开始和结束事件)发生变化时,聚合数据会过时。这可以通过每天进行的定期聚合来解决。
功能可用性
聚合VSA功能在组和项目级别可用,但聚合后端仅对Premium和Ultimate客户开放,因为数据存储和计算成本较高。存储非规范化、聚合后的数据需要大量磁盘空间。
聚合价值流分析架构
聚合VSA后端的核心思想是分离:VSA数据库表和查询不直接使用核心领域模型(Issue、MergeRequest)。这使得我们可以独立于应用的其他部分来扩展和优化VSA。
该架构由两个主要机制组成:
- 定期数据收集与加载(在后台进行)。
- 查询收集到的数据(由用户触发)。
数据加载
VSA 的聚合特性源于定期数据加载。系统会查询核心领域模型来收集阶段和时间戳数据,这些数据会被定期插入到 VSA 数据库表中。
针对拥有 Premium 或 Ultimate 许可证的每个顶级命名空间的概览:
- 加载组内的所有阶段。
- 遍历问题和合并请求记录。
- 基于阶段配置(开始和结束事件标识符)收集时间戳数据。
- 将数据
INSERT或UPDATE到 VSA 数据库表中。
数据加载由 Analytics::CycleAnalytics::DataLoaderService 类实现。有些组包含大量数据,为了避免给主数据库造成过载,该服务采用分批操作并强制执行严格的应用限制:
- 分批加载记录。
- 分批插入记录。
- 当达到限制时停止处理,安排后台作业稍后继续处理。
- 从特定点继续处理数据。
数据加载目前是手动执行的。一旦功能准备就绪,系统将通过 cron 作业定期调用该服务(此部分尚未实现)。
记录迭代
分批迭代通过 高效的 IN 运算符 实现。后台作业会扫描组层次结构中所有问题和合并请求记录,按 updated_at 和 id 列排序。对于已聚合的组,DataLoaderService 会从特定点继续聚合,从而节省时间。
每次迭代都会收集时间戳数据。DataLoaderService 会确定组层次结构中配置的阶段事件,并构建查询以选择所需的时间戳。阶段记录知道配置了哪些事件,而事件则知道如何选择时间戳列。
收集到的阶段事件示例如下:合并请求合并、合并请求创建、合并请求关闭。
用于加载时间戳的生成 SQL 查询:
SELECT
-- 列表取决于配置的阶段
"merge_request_metrics"."merged_at",
"merge_requests"."created_at",
"merge_request_metrics"."latest_closed_at"
FROM "merge_requests"
LEFT OUTER JOIN "merge_request_metrics" ON "merge_request_metrics"."merge_request_id" = "merge_requests"."id"
WHERE "merge_requests"."id" IN (1, 2, 3, 4) -- ID 来自分批查询merged_at 列位于单独的表(merge_request_metrics)中。Gitlab::Analytics::CycleAnalytics::StagEvents::MergeRequestMerged 类会将自身添加到一个作用域中,以便在不影响行数的情况下加载数据(使用 LEFT JOIN)。这种行为通过 include_in 方法为每个 StageEvent 类实现。
数据收集查询基于事件级别运行。它会从阶段中提取事件时间戳,并确保不会多次收集相同的数据。上述事件可能来自以下阶段配置:
- 合并请求创建 → 合并请求合并
- 合并请求创建 → 合并请求关闭
其他组合也可能存在,但我们阻止了无意义的组合,例如:
- 合并请求合并 → 合并请求创建
创建时间总是先发生,因此这种阶段始终会报告负时长。
数据范围
数据收集会扫描并处理组层次结构中所有问题和合并请求记录,从顶级组开始。这意味着,如果一个组仅在子组中有一个价值流,我们仍会收集该组层次结构中所有问题和合并请求的数据。这旨在简化数据收集机制。此外,研究显示大多数组的层次结构会在顶级配置阶段。
在数据收集过程中,收集到的时间戳数据会被转换为行。对于每个配置的阶段,如果存在开始事件时间戳,系统会插入或更新一条事件记录。这使我们能够通过统计所有问题和合并请求的数量,并将其乘以阶段数量来确定每组插入行的上限。
数据一致性考量
由于数据收集的异步特性,数据一致性问题必然会出现。这是一种权衡,它显著提升了查询性能。我们认为,对于分析工作负载而言,数据的轻微延迟是可以接受的。
在发布前,我们计划在 VSA 页面实现一些指标,显示最近的后端活动。例如,显示上次数据收集时间戳和上次一致性检查时间戳的指标。