读多写少数据
本文介绍了 数据库可扩展性工作组 提出的 读多写少 模式。我们将讨论 读多写少 数据的特征,并为 GitLab 开发提出在此背景下应考虑的最佳实践。
读多写少数据的特征
顾名思义,读多写少 数据是指读取频率远高于更新频率的数据。与读取相比,通过更新、插入或删除来写入此类数据是非常罕见的事件。
此外,此处的 读多写少 数据通常是小型数据集。我们明确不处理大型数据集,尽管它们也常常具有"一次写入,频繁读取"的特征。
示例:许可证数据
我们来介绍一个典型示例:GitLab 中的许可证数据。一个 GitLab 实例可能附加了一个许可证以使用 GitLab 企业功能。此许可证数据是实例范围的,即通常只存在少量相关记录。这些信息保存在一个名为 licenses 的表中,该表非常小。
我们认为这是 读多写少 数据,因为它符合上述特征:
- 写入稀少:许可证数据在插入许可证后几乎不会发生任何写入。
- 读取频繁:许可证数据被频繁读取以检查是否可以使用企业功能。
- 规模小:此数据集非常小。在 GitLab.com 上,我们有 5 条记录,总关系大小小于 50 kB。
规模化 读多写少 数据的影响
鉴于此数据集规模小且读取频繁,我们可以预期数据几乎总是驻留在数据库缓存和/或数据库磁盘缓存中。因此,读多写少 数据的关注点通常不在于数据库 I/O 开销,因为我们通常不会从磁盘读取数据。
然而,考虑到高频读取,这可能会在数据库 CPU 负载和数据库上下文切换方面产生开销。此外,这些高频查询会贯穿整个数据库堆栈。它们还会在数据库连接复用组件和负载均衡器上造成开销。同时,应用程序会花费周期来准备和发送查询以检索数据、反序列化结果并分配新对象来表示收集到的信息——所有这些都以高频方式进行。
在上述许可证数据示例中,读取许可证数据的查询在查询频率方面 被识别 为突出。事实上,在高峰时段,我们在集群上看到了大约 6,000 次查询/秒(QPS)。当时的集群规模下,我们在每个副本上看到约 1,000 QPS,在主库上看到少于 400 QPS。这种差异由我们的 数据库负载均衡以扩展读取 解释,该方案倾向于为纯只读事务使用副本。
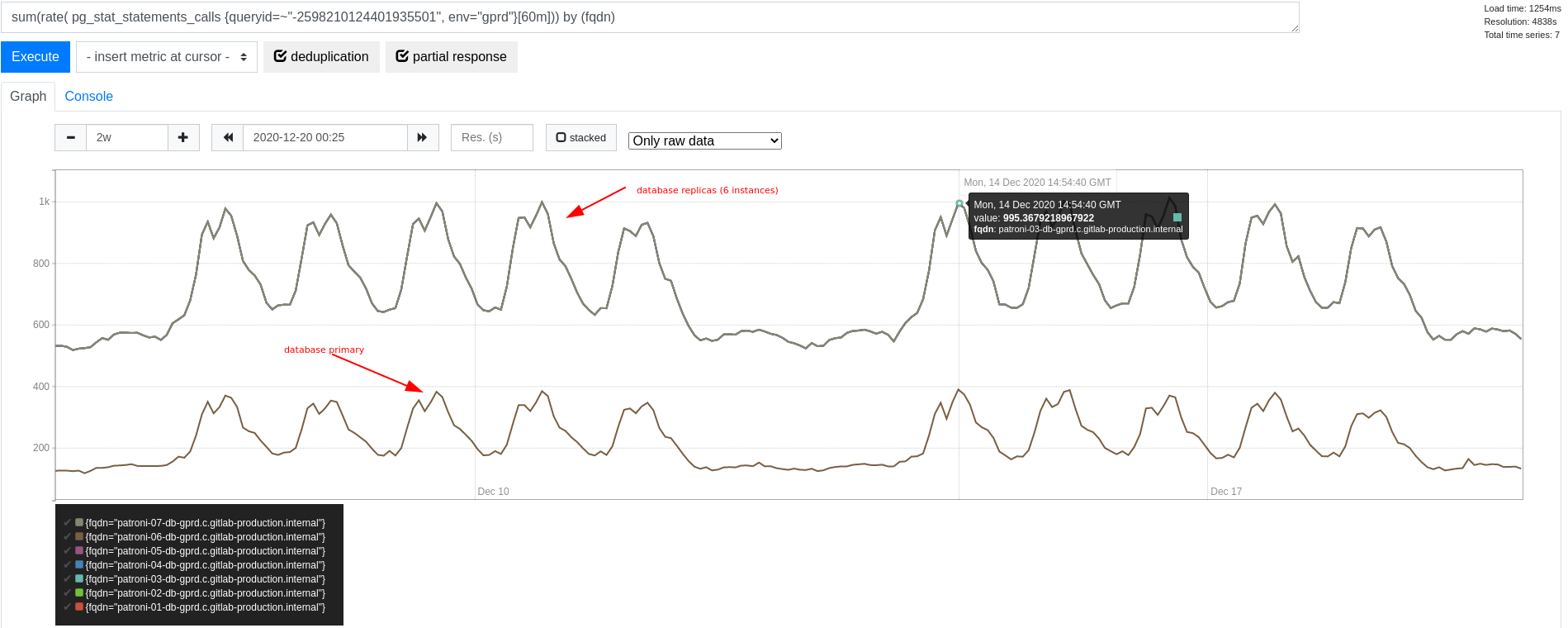
当时,数据库主库的整体事务吞吐量在每秒 50,000 到 70,000 个事务(TPS)之间变化。相比之下,此查询频率仅占整体查询频率的一小部分。然而,我们确实预期这仍会在上下文切换方面产生相当大的开销。如果可能,值得消除此开销。
如何识别读多写少数据
识别 读多写少 数据可能很困难,尽管在我们的示例中有明确的案例。
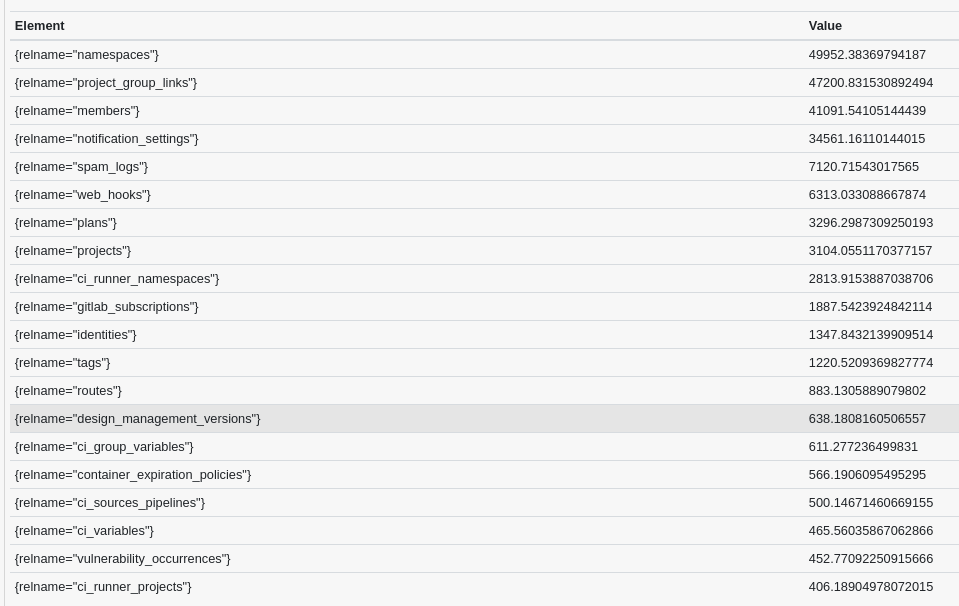
一种方法是查看 例如来自主库的读写比和统计信息。在这里,我们根据 60 分钟内的读写比查看 TOP20 表(在高峰流量时段采集):
bottomk(20,
avg by (relname, fqdn) (
(
rate(pg_stat_user_tables_seq_tup_read{env="gprd"}[1h])
+
rate(pg_stat_user_tables_idx_tup_fetch{env="gprd"}[1h])
) /
(
rate(pg_stat_user_tables_seq_tup_read{env="gprd"}[1h])
+ rate(pg_stat_user_tables_idx_tup_fetch{env="gprd"}[1h])
+ rate(pg_stat_user_tables_n_tup_ins{env="gprd"}[1h])
+ rate(pg_stat_user_tables_n_tup_upd{env="gprd"}[1h])
+ rate(pg_stat_user_tables_n_tup_del{env="gprd"}[1h])
)
) and on (fqdn) (pg_replication_is_replica == 0)
)这很好地展示了哪些表的读取频率远高于写入频率(在数据库主库上):
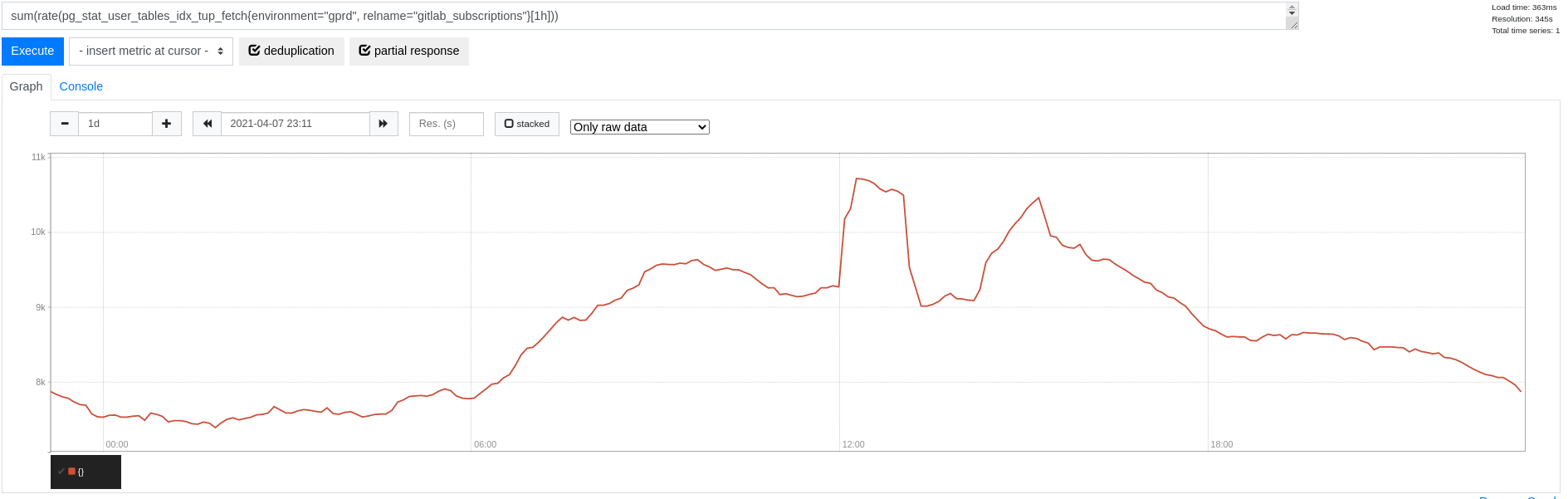
从这里,我们可以 放大 查看 gitlab_subscriptions 表,并意识到索引读取的峰值总体上超过每秒 10k 个元组(没有顺序扫描):
我们很少对该表进行写入(没有顺序扫描):
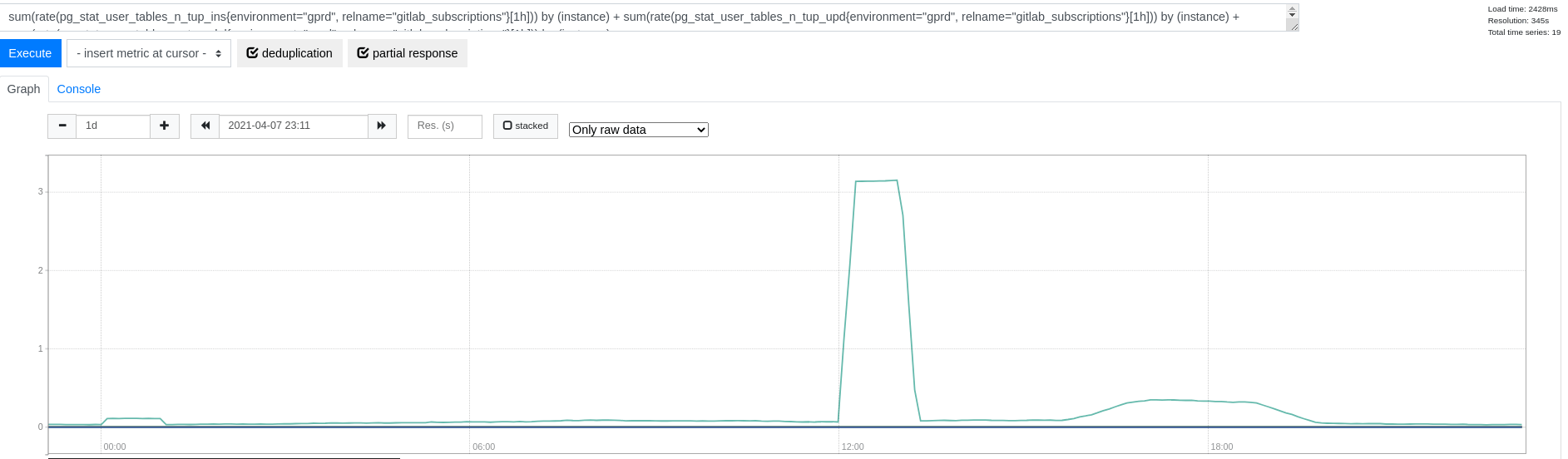
此外,该表的大小仅为 400 MB——因此这可能是我们在此模式中考虑的另一个候选对象(参见 #327483)。
规模化处理读多写少数据的最佳实践
缓存读多写少数据
为了减少数据库开销,我们为数据实现缓存,从而显著降低数据库端的查询频率。可用的缓存范围包括:
`RequestStore: 每请求内存缓存(基于request_storegem)- ``
[ProcessMemoryCache](https://gitlab.com/gitlab-org/gitlab/blob/master/lib/gitlab/process_memory_cache.rb#L4): 每进程内存缓存(一个ActiveSupport::Cache::MemoryStore) - ``
[Gitlab::Redis::Cache](https://gitlab.com/gitlab-org/gitlab/blob/master/lib/gitlab/redis/cache.rb)和Rails.cache: Redis 中的完整缓存`
继续上述示例,我们使用了 RequestStore 来按请求缓存许可证信息。然而,这仍然导致每个请求一次查询。当我们开始使用 进程范围的内存缓存 缓存许可证信息 1 秒时,查询频率显著下降:
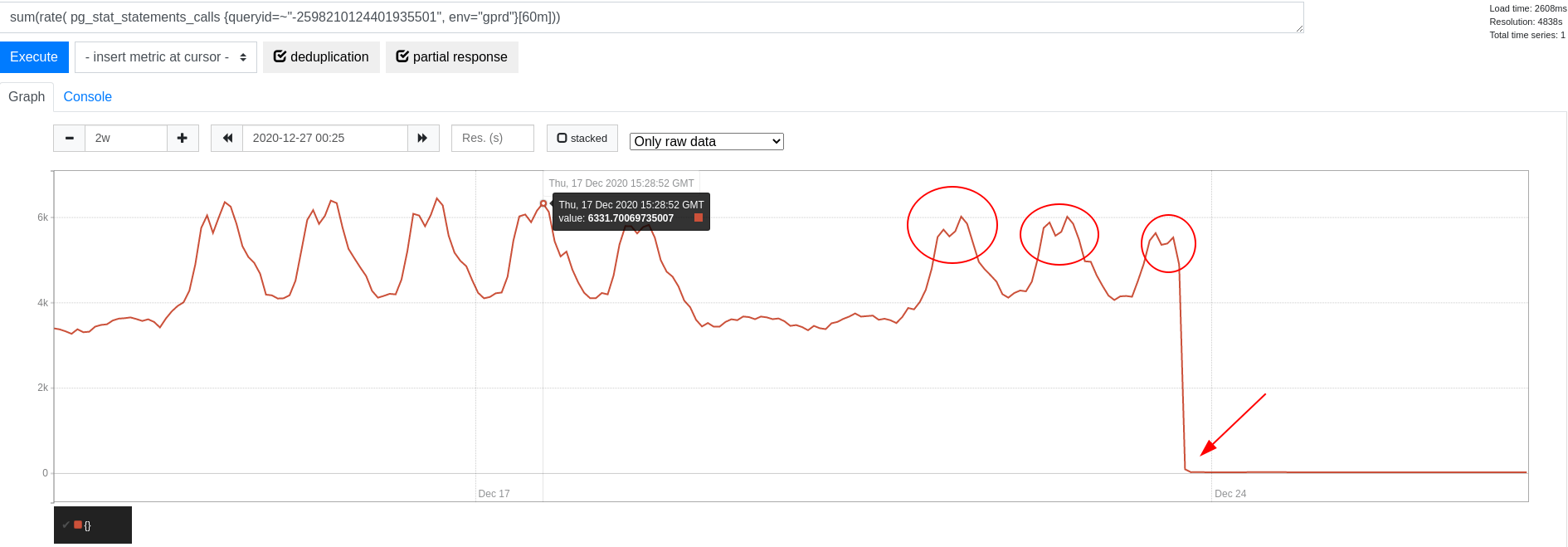
此处缓存的选择高度取决于所讨论数据的特征。像许可证数据这样几乎从不更新的极小数据集是内存缓存的良好候选。每进程缓存在这里是有利的,因为它将缓存刷新速率与传入请求速率解耦。
这里的一个注意事项是,我们的 Redis 设置目前没有使用 Redis 从库,我们依赖单个节点进行缓存。也就是说,我们需要取得平衡以避免 Redis 因压力过大而崩溃。相比之下,从 PostgreSQL 副本读取数据可以分布在多个只读副本上。尽管对数据库的查询可能更昂贵,但负载分布在更多节点上。
从副本读取读多写少数据
无论是否实现缓存,我们还必须确保尽可能从数据库副本读取数据。这支持我们在多个数据库副本上扩展读取的努力,并从数据库主库中移除不必要的工作负载。
GitLab 数据库负载均衡以扩展读取 在第一次写入或打开显式事务后会坚持使用主库。在 读多写少 数据的上下文中,我们努力在事务范围之外且在进行任何写入之前读取此数据。鉴于此数据很少更新(因此我们通常不关心读取略微过时的数据),这通常是可行的。然而,由于之前的写入或事务,此查询无法发送到副本可能并不明显。因此,当我们遇到 读多写少 数据时,检查更广泛的上下文并确保此数据可以从副本读取是一种良好的实践。