批量后台迁移
当迁移超过我们指南中的时间限制时,应使用批量后台迁移来执行数据迁移。例如,你可以使用批量后台迁移将存储在单个 JSON 列中的数据迁移到单独的表中。
批量后台迁移取代了旧的后台迁移框架。有关涉及该框架的任何更改,请查阅相关文档。
批量后台迁移框架支持 ChatOps。通过 ChatOps,GitLab 工程师可以与系统中现有的批量后台迁移进行交互。
何时使用批量后台迁移
当使用常规 Rails 迁移执行时会超过我们指南中的时间限制,应在包含大量行的表中迁移数据时使用批量后台迁移。
-
在迁移高流量表中的数据时,应使用批量后台迁移。
-
当对大型数据集中的每个项目执行大量单行查询时,也可以使用批量后台迁移。通常,对于单记录模式,运行时间很大程度上取决于数据集的大小。相应地拆分数据集,并将其放入后台迁移。
-
不要使用批量后台迁移来执行架构迁移。
后台迁移可以在以下情况下帮助:
-
将事件从一个表迁移到多个单独的表中。
-
基于存储在另一列中的 JSON 填充一列。
-
迁移依赖于外部服务输出的数据。(例如,API。)
注意事项
-
如果批量后台迁移是重要升级的一部分,则必须在发布帖子中宣布。如果您不确定迁移是否属于此类,请与您的项目经理讨论。
-
你应该使用生成器创建批量后台迁移,以便默认创建所需的文件。
批量后台迁移的工作原理
批量后台迁移(BBM)是 Gitlab::BackgroundMigration::BatchedMigrationJob 的子类,定义了一个 perform 方法。作为第一步,常规迁移会创建一个包含 BBM 类和所需参数的 batched_background_migrations 记录。默认情况下,batched_background_migrations 处于活动状态,并由 Sidekiq worker 拾取以执行实际的批量迁移。
所有迁移类都必须在命名空间 Gitlab::BackgroundMigration 中定义。将文件放在目录 lib/gitlab/background_migration/ 中。
执行机制
批量后台迁移按入队顺序从队列中选取。只要它们处于活动状态且不针对同一数据库表,就会获取并并行执行多个迁移。默认并行处理的迁移数量为 2,对于 GitLab.com,此限制配置为 4。一旦选择迁移执行,将为特定批次创建一个作业。每次作业执行后,根据最后 20 个作业的性能,迁移的批大小可能会增加或减少。
@startuml
hide empty description
skinparam ConditionEndStyle hline
left to right direction
rectangle "Batched background migration queue" as migrations {
rectangle "Migration N (active)" as migrationn
rectangle "Migration 1 (completed)" as migration1
rectangle "Migration 2 (active)" as migration2
rectangle "Migration 3 (on hold)" as migration3
rectangle "Migration 4 (active)" as migration4
migration1 -[hidden]> migration2
migration2 -[hidden]> migration3
migration3 -[hidden]> migration4
migration4 -[hidden]> migrationn
}
rectangle "Execution Workers" as workers {
rectangle "Execution Worker 1 (busy)" as worker1
rectangle "Execution Worker 2 (available)" as worker2
worker1 -[hidden]> worker2
}
migration2 --> [Scheduling Worker]
migration4 --> [Scheduling Worker]
[Scheduling Worker] --> worker2
@enduml
一旦 worker 可用,BBM 将由 runner 处理。
@startuml
hide empty description
start
rectangle 运行器 {
:迁移;
if (是否达到批处理边界?) then (是)
if (有待重试的作业?) then (是)
:获取批处理作业;
else (否)
:完成活跃迁移;
stop
endif
else (否)
:创建批处理作业;
endif
:执行批处理作业;
:评估数据库健康状态;
note right: 检查表自动清理(autovacuum)、Patroni Apdex 和预写日志(Write - ahead logging)
if (评估结果需停止?) then (是)
:将迁移置于暂停状态;
else (否)
:优化迁移;
endif
}
@enduml
幂等性
批处理后台迁移在 Sidekiq 进程的上下文中执行。通常的 Sidekiq 规则适用,尤其是作业应小巧且幂等的规则。确保当你的迁移作业重试时,数据完整性得到保证。
详见 Sidekiq 最佳实践指南 了解更多细节。
迁移优化
每次作业执行后,会进行验证以检查迁移是否可优化。优化的底层机制基于时间效率的概念。它计算最近 N 个作业的时间效率指数移动平均值,并将批处理后端迁移的批量大小更新为其最优值。
然而,使用 数据库迁移管道 时,此机制使我们难以提供迁移总执行时间的准确估计。
我们正在讨论解决此问题的方法,详情见 此问题。
作业重试机制
批处理后台迁移的重试机制确保作业在失败时再次执行。下图展示了我们重试机制的不同阶段:
@startuml
hide empty description
note as N1
can_split?:
失败是由于查询超时导致的
end note
[*] --> 运行中
运行中 --> 失败
note on link
若重试次数 ≤ MAX_ATTEMPTS
end note
运行中 --> 成功
失败 --> 运行中
note on link
若重试次数 > MAX_ATTEMPTS
且 can_split? 为 true
则创建两个批量更小的作业
end note
失败 --> [*]
成功 --> [*]
@enduml
MAX_ATTEMPTS在Gitlab::Database::BackgroundMigration类中定义。can_split?在Gitlab::Database::BatchedJob类中定义。
失败的批处理后台迁移
如果满足以下任一条件,整个批处理后端迁移将被标记为 failed(/chatops run batched_background_migrations status MIGRATION_ID 显示迁移为 failed):
- 没有更多作业可供消费,并且存在失败的作业。
- 自后台迁移开始以来,超过一半的作业失败(参考 此处)。
批处理迁移节流
由于批处理迁移更新量很大,并且在数据库性能不佳时因这些迁移的重负载导致过事故,因此存在节流机制来缓解未来事故。
会检查这些数据库指标以对迁移进行节流。收到停止信号后,迁移将暂停一段设定时间(10 分钟):
- WAL 队列待归档数量超过阈值。
- 迁移所操作的表上的活动自动清理(自 GitLab 18.0 起默认启用)。
- Patroni apdex SLI 低于 SLO。
- WAL 速率超过阈值。
目前正在努力添加更多指标以进一步增强数据库健康检查框架。有关详细信息,请参阅 epic 7594。
如何禁用/启用表的自动清理指标
自 GitLab 18.0 起,此健康指标默认启用。若要禁用它,请在 Rails 控制台中运行以下命令:
Feature.disable(:batched_migrations_health_status_autovacuum)或者,如果要重新启用它,请在 Rails 控制台中运行以下命令:
Feature.enable(:batched_migrations_health_status_autovacuum)隔离性
批处理后端迁移必须隔离,不能使用应用程序代码(例如,app/models 中定义的模型,除 ApplicationRecord 类外)。因为这些迁移可能需要很长时间才能运行,所以在迁移仍在运行时部署新版本是有可能的。
依赖已迁移的数据
与常规迁移或后迁移不同,等待下一个版本发布并不能保证数据已完全迁移。这意味着在BBM(批处理后台迁移)完成之前,你不应该依赖这些数据。如果要求100%的数据都已迁移,那么可以使用 ensure_batched_background_migration_is_finished 辅助方法来确保迁移已完成且数据已完全迁移。(查看示例)
如何操作
生成批处理后台迁移
自定义生成器 batched_background_migration 会搭建必要的文件,并接受 table_name、column_name 和 feature_category 作为参数。选择 column_name 时,请确保使用可以明确迭代的列类型,最好是表的主键。表将根据此处定义的列进行迭代。更多信息,请参见 对非唯一列进行分批处理。
用法:
bundle exec rails g batched_background_migration my_batched_migration --table_name=<table-name> --column_name=<column-name> --feature_category=<feature-category>此命令会创建以下文件:
db/post_migrate/20230214231008_queue_my_batched_migration.rbspec/migrations/20230214231008_queue_my_batched_migration_spec.rblib/gitlab/background_migration/my_batched_migration.rbspec/lib/gitlab/background_migration/my_batched_migration_spec.rb
入队批处理后台迁移
入队批处理后台迁移应在部署后迁移中完成。使用此 queue_batched_background_migration 示例,将迁移入队以分批执行。将类名和参数替换为你的迁移中的值:
queue_batched_background_migration(
JOB_CLASS_NAME,
TABLE_NAME,
JOB_ARGUMENTS
)如果提供的作业参数数量与 JOB_CLASS_NAME 中定义的作业参数数量不匹配,该辅助方法会抛出错误。
确保新创建的数据要么已迁移,要么在创建时同时保存到旧版和新版中。删除操作则可以通过定义带有级联删除的外键来处理。
完成批处理后台迁移
完成批处理后台迁移是通过调用 ensure_batched_background_migration_is_finished 来实现的,但仅当迁移是在最后一个必需停止点之前添加的。这能确保GitLab自托管实例的升级过程顺畅。
在安全的情况下完成所有批处理后台迁移很重要。遗留旧的批处理后台迁移是一种技术债务,需要在测试和应用程序行为中进行维护。
在任何批处理后台迁移完成之前,你不能依赖它。
我们建议在满足以下所有条件后再完成批处理后台迁移:
- 该批处理后台迁移已在GitLab.com上完成
- 该批处理后台迁移是在最后一个必需停止点之前添加的。例如,如果17.8是一个必需停止点,而迁移是在17.7中添加的,那么完成迁移可以在17.9中添加。
ensure_batched_background_migration_is_finished 调用必须与用于入队的迁移完全匹配。请注意以下几点:
- 作业参数:需要完全匹配,否则将找不到已入队的迁移
gitlab_schema:需要完全匹配,否则将找不到已入队的迁移。即使表的gitlab_schema在此期间从gitlab_main变更为gitlab_main_cell,如果在入队批处理后台迁移时使用了gitlab_main,则必须使用gitlab_main来完成它。
在完成批处理后台迁移时,你还需要更新相应 db/docs/batched_background_migrations 文件中的 finalized_by。其值应为你添加的用于完成迁移的迁移的时间戳/版本号。
有关实际迁移代码的具体细节,请参阅下文示例。
如果在入队后的一个必需停止点之前完成迁移,则会引发早期完成错误。如果迁移需要在入队后的一个必需停止点之前完成,请使用 skip_early_finalization_validation: true 选项跳过此检查。
删除批处理后台迁移代码
当批量后台迁移完成、最终确定且未被重新排队时,在最终确定后的下一个必需停止点之后,可以删除lib/gitlab/background_migration/中的迁移代码及其相关测试。
以下是示例场景:
- 17.3和17.5是必需停止点。
- 在17.1中,批量后台迁移被排队。
- 在17.4中,若该迁移已在GitLab.com上完成,则可将其最终确定。
- 在17.6中,与该迁移相关的代码可以被删除。
批量后台迁移代码通常会在迁移被压缩时被定期删除。
重新排队批量后台迁移
批量后台迁移可能因以下几种原因需要重新运行:
要重新排队一个批量后台迁移,你必须:
- 对原始迁移文件的
#up和#down方法的内容进行空操作(no-op)。否则,在同时升级多个补丁版本的系统中,批量后台迁移会被创建、删除,然后再一次创建。 - 添加一个新的发布后迁移(post-deployment migration),以重新运行批量后台迁移。
- 在新的发布后迁移中,在
#up方法的起始处使用delete_batched_background_migration方法删除现有的批量后台迁移,以确保清理任何现有的运行记录。 - 更新原始迁移对应的
db/docs/batched_background_migration/*.yml文件,以包含关于重新排队的详细信息。
示例
原始迁移:
# frozen_string_literal: true
class QueueResolveVulnerabilitiesForRemovedAnalyzers < Gitlab::Database::Migration[2.2]
milestone '17.3'
MIGRATION = "ResolveVulnerabilitiesForRemovedAnalyzers"
def up
# 无操作,因为原始迁移存在错误,已通过以下方式修复
end
def down
# 无操作,因为原始迁移存在错误,已在https://gitlab.com/gitlab-org/gitlab/-/merge_requests/162527中修复
end
end重新排队的迁移:
# frozen_string_literal: true
class RequeueResolveVulnerabilitiesForRemovedAnalyzers < Gitlab::Database::Migration[2.2]
milestone '17.4'
restrict_gitlab_migration gitlab_schema: :gitlab_main
MIGRATION = "ResolveVulnerabilitiesForRemovedAnalyzers"
BATCH_SIZE = 10_000
SUB_BATCH_SIZE = 100
def up
# 清理之前由QueueResolveVulnerabilitiesForRemovedAnalyzers执行的背景迁移
delete_batched_background_migration(MIGRATION, :vulnerability_reads, :id, [])
queue_batched_background_migration(
MIGRATION,
:vulnerability_reads,
:id,
batch_size: BATCH_SIZE,
sub_batch_size: SUB_BATCH_SIZE
)
end
def down
delete_batched_background_migration(MIGRATION, :vulnerability_reads, :id, [])
end
end批量迁移字典:
milestone和queued_migration_version应为重新排队迁移的值(本例中为RequeueResolveVulnerabilitiesForRemovedAnalyzers)。
---
migration_job_name: ResolveVulnerabilitiesForRemovedAnalyzers
description: 解决所有检测到的已移除分析器的漏洞。
feature_category: static_application_security_testing
introduced_by_url: https://gitlab.com/gitlab-org/gitlab/-/merge_requests/162691
milestone: '17.4'
queued_migration_version: 20240814085540
finalized_by: # 最终确定此BBM的迁移版本停止并移除批量后台迁移
处于运行状态的批量后台迁移可因多种原因被停止和移除:
- 当迁移不再相关或必需,因为产品用例发生了变化。
- 该迁移必须被另一个具有不同逻辑的迁移所取代。
要停止并移除正在进行的批量后台迁移,你必须:
- 在Release N中,对调度数据库迁移的
#up和#down方法的内容进行空操作。
class BackfillNamespaceType < Gitlab::Database::Migration[2.1]
# 不再需要BBM的原因。例如:此BBM不再需要,因为它将被另一个具有不同逻辑的BBM取代。
def up; end
def down; end
end- 在Release N中,添加一个常规迁移来删除现有的批量迁移。在
#up方法的起始处使用delete_batched_background_migration方法删除现有的批量后台迁移,以确保清理任何现有的运行记录。
class CleanupBackfillNamespaceType < Gitlab::Database::Migration[2.1]
MIGRATION = "MyMigrationClass"
restrict_gitlab_migration gitlab_schema: :gitlab_main
def up
delete_batched_background_migration(MIGRATION, :vulnerabilities, :id, [])
end
def down; end
end在版本N中,还需删除迁移类文件(lib/gitlab/background_migration/my_batched_migration.rb)及其测试。
以上所有步骤均可在一个MR中实现。
使用作业参数
BatchedMigrationJob 提供了 job_arguments 辅助方法,供作业类定义所需的作业参数。
通过 queue_batched_background_migration 调度的批量迁移必须使用该辅助方法定义作业参数:
queue_batched_background_migration(
'CopyColumnUsingBackgroundMigrationJob',
TABLE_NAME,
'name', 'name_convert_to_text'
)如果定义的作业参数数量与调度迁移时提供的作业参数数量不匹配,queue_batched_background_migration 会抛出错误。
在此示例中,copy_from 返回 name,copy_to 返回 name_convert_to_text:
class CopyColumnUsingBackgroundMigrationJob < BatchedMigrationJob
job_arguments :copy_from, :copy_to
operation_name :update_all
def perform
from_column = connection.quote_column_name(copy_from)
to_column = connection.quote_column_name(copy_to)
assignment_clause = "#{to_column} = #{from_column}"
each_sub_batch do |relation|
relation.update_all(assignment_clause)
end
end
end使用过滤器
默认情况下,当创建后台作业执行迁移时,批量后台迁移会遍历整个指定表。此迭代通过 PrimaryKeyBatchingStrategy 完成。若表有1000条记录且分批大小为100,工作会被分成10个作业。为便于说明,EachBatch 的用法如下:
# PrimaryKeyBatchingStrategy
Namespace.each_batch(of: 100) do |relation|
relation.where(type: nil).update_all(type: 'User') # 此操作在每个后台作业中执行
end使用复合或部分索引迭代表的子集
应用额外过滤器时,需确保它们被适当 索引覆盖,以优化 EachBatch 性能。以下示例中,我们需要一个 (type, id) 或 id WHERE type IS NULL 索引来支持过滤器。更多信息请参阅 EachBatch 文档。
若有合适索引且只想迭代表的子集,可在 each_batch 前应用 where 子句,例如:
# 若存在以下任一索引则效果良好:
# - `id WHERE type IS NULL`
# - `(type, id)`
# 否则效果不佳。
Namespace.where(type: nil).each_batch(of: 100) do |relation|
relation.update_all(type: 'User')
end这种方法的优势是可获得一致的批处理大小,但仅适用于存在与 where 子句及分批策略匹配的索引的场景。
BatchedMigrationJob 提供 scope_to 辅助方法来应用额外过滤器并实现这一点:
- 创建一个新的迁移作业类,继承自
BatchedMigrationJob并定义额外过滤器:
class BackfillNamespaceType < BatchedMigrationJob
# 若存在以下任一索引则效果良好:
# - `id WHERE type IS NULL`
# - `(type, id)`
# 否则效果不佳。
scope_to ->(relation) { relation.where(type: nil) }
operation_name :update_all
feature_category :source_code_management
def perform
each_sub_batch do |sub_batch|
sub_batch.update_all(type: 'User')
end
end
end对于定义了 scope_to 的EE迁移,请确保模块扩展了 ActiveSupport::Concern。否则,记录会被处理而不考虑范围。
- 在部署后迁移中,入队批量后台迁移:
class BackfillNamespaceType < Gitlab::Database::Migration[2.1]
MIGRATION = 'BackfillNamespaceType'
restrict_gitlab_migration gitlab_schema: :gitlab_main
def up
queue_batched_background_migration(
MIGRATION,
:namespaces,
:id
)
end
def down
delete_batched_background_migration(MIGRATION, :namespaces, :id, [])
end
end访问多数据库的数据
背景
与常规迁移不同,后台迁移可以访问多个数据库,并能高效地跨数据库访问和更新数据。为了正确指示要使用的数据库,建议在迁移代码中内联创建ActiveRecord模型。此类模型应基于表所在数据库使用正确的ApplicationRecord。因此,禁止使用ActiveRecord::Base,因为它未明确指定访问给定表时要使用的数据库。
# 好
class Gitlab::BackgroundMigration::ExtractIntegrationsUrl
class Project < ::ApplicationRecord
self.table_name = 'projects'
end
class Build < ::Ci::ApplicationRecord
self.table_name = 'ci_builds'
end
end
# 坏
class Gitlab::BackgroundMigration::ExtractIntegrationsUrl
class Project < ActiveRecord::Base
self.table_name = 'projects'
end
class Build < ActiveRecord::Base
self.table_name = 'ci_builds'
end
end同样,禁止使用ActiveRecord::Base.connection,最好替换为使用模型连接。
# 好
Project.connection.execute("SELECT * FROM projects")
# 可接受
ApplicationRecord.connection.execute("SELECT * FROM projects")
# 坏
ActiveRecord::Base.connection.execute("SELECT * FROM projects")非唯一列的分批处理
默认的分批策略提供了高效遍历主键列的方式。但是,如果需要遍历值不唯一的列,则必须使用不同的分批策略。
LooseIndexScanBatchingStrategy分批策略使用特殊的EachBatch,以提供对唯一列值的高效稳定迭代。
此示例展示了使用issues.project_id列作为分批列的批量后台迁移。
数据库迁移后:
class ProjectsWithIssuesMigration < Gitlab::Database::Migration[2.1]
MIGRATION = 'BatchProjectsWithIssues'
BATCH_SIZE = 5000
SUB_BATCH_SIZE = 500
restrict_gitlab_migration gitlab_schema: :gitlab_main
disable_ddl_transaction!
def up
queue_batched_background_migration(
MIGRATION,
:issues,
:project_id,
batch_size: BATCH_SIZE,
batch_class_name: 'LooseIndexScanBatchingStrategy', # 覆盖默认分批策略
sub_batch_size: SUB_BATCH_SIZE
)
end
def down
delete_batched_background_migration(MIGRATION, :issues, :project_id, [])
end
end实现后台迁移类:
module Gitlab
module BackgroundMigration
class BatchProjectsWithIssues < Gitlab::BackgroundMigration::BatchedMigrationJob
include Gitlab::Database::DynamicModelHelpers
operation_name :backfill_issues
def perform
distinct_each_batch do |batch|
project_ids = batch.pluck(batch_column)
# 对唯一的 project_ids 执行操作
end
end
end
end
end由scope_to定义的附加过滤器会被LooseIndexScanBatchingStrategy和distinct_each_batch忽略。
计算批量后台迁移的总时间估计
可以估计BBM(批量后台迁移)完成所需的时间。GitLab已通过db:gitlabcom-database-testing管道提供估算。该估算基于测试环境中生产数据的采样,代表迁移可能花费的最长时间,而非实际时间。在某些场景下,db:gitlabcom-database-testing管道提供的估算可能不足以计算被迁移记录的所有特殊性,从而需要进行进一步计算。如有必要,可使用公式interval * 记录数 / 最大批次大小来确定迁移大约需要多长时间。其中interval和最大批次大小是指作业定义的选项,总元组数是要迁移的记录数量。
估算可能会受到迁移优化机制的影响。
清理批量后台迁移
清理任何剩余的后台迁移必须在主要或次要版本中进行。不得在补丁版本中执行此操作。
由于后台迁移可能耗时很久,因此在排队后无法立即清理。例如,不能删除迁移过程中使用的列,否则作业会失败。必须在未来的发布中加入单独的_后部署_迁移,先完成剩余作业,再进行清理(例如,删除列)。
要将数据从包含大型JSON对象的列 foo 迁移到包含字符串的列 bar,您可以:
-
发布版本A:
-
创建一个迁移类,用于对给定ID的行执行迁移。
-
使用以下技术之一更新新行:
-
为不需要应用程序逻辑的复制操作创建新触发器。
-
在记录创建或更新时在模型/服务中处理此操作。
-
创建一个新的自定义后台作业来更新记录。
-
-
在发布后迁移中为所有现有行排队批量后台迁移。
-
-
发布版本B:
-
添加一个发布后迁移,检查批量后台迁移是否完成。
-
部署代码,使应用程序开始使用新列并停止更新新记录。
-
删除旧列。
-
如果从GitLab先前版本导入项目需要数据采用新格式,则可能需要增加导入/导出版本。
添加索引以支持批量后台迁移
有时有必要添加新的或临时的索引来支持批量后台迁移。为此,请在排定后台迁移的发布后迁移之前创建该索引。
有关某些特殊情况需要特别注意的信息,请参阅添加数据库索引文档,这些情况允许索引在创建后直接使用。
在数据库测试管道上执行特定批次
只有数据库维护者可以查看数据库测试管道工件。如果您需要使用此方法,请向他们寻求帮助。
假设在GitLab.com上的某个批次批量后台迁移失败,您想找出哪个查询失败以及原因。目前,我们没有一个好的方法来检索查询信息(尤其是查询参数),而重新运行整个迁移并启用更多日志记录将是一个漫长的过程。
幸运的是,您可以利用我们的数据库迁移管道重新运行特定批次,并添加额外日志记录和/或修复,看看是否能解决问题。
示例请参见草稿:Test PG::CardinalityViolation修复,但确保阅读整个部分。
要这样做,您需要:
查找批次的 start_id 和 end_id
您应该在Kibana中找到它们。
创建常规迁移
在常规迁移的 up 块中安排批次:
def up
instance = Gitlab::BackgroundMigration::YourBackgroundMigrationClass.new(
start_id: <batch start_id>,
end_id: <batch end_id>,
batch_table: <table name>,
batch_column: <batching column>,
sub_batch_size: <sub batch size>,
pause_ms: <milliseconds between batches>,
job_arguments: <job arguments if any>,
connection: connection
)
instance.perform
end
def down
# 无操作
end应用针对我们的迁移助手的解决方法(可选)
如果您的批量后台迁移使用了与通过 restrict_gitlab_migration 助手指定的模式不同的模式的表(例如:调度迁移有 restrict_gitlab_migration gitlab_schema: :gitlab_main 但后台作业使用了 :gitlab_ci 模式的表),则迁移将失败。为防止这种情况发生,您必须对数据库助手进行猴子补丁,使其不会导致测试管道作业失败:
- 将架构名称添加到
RestrictGitlabSchema
diff --git a/lib/gitlab/database/migration_helpers/restrict_gitlab_schema.rb b/lib/gitlab/database/migration_helpers/restrict_gitlab_schema.rb
index b8d1d21a0d2d2a23d9e8c8a0a17db98ed1ed40b7..912e20659a6919f771045178c66828563cb5a4a1 100644
--- a/lib/gitlab/database/migration_helpers/restrict_gitlab_schema.rb
+++ b/lib/gitlab/database/migration_helpers/restrict_gitlab_schema.rb
@@ -55,7 +55,7 @@ def unmatched_schemas
end
def allowed_schemas_for_connection
- Gitlab::Database.gitlab_schemas_for_connection(connection)
Gitlab::Database.gitlab_schemas_for_connection(connection) << :gitlab_ci\n```\n\n1. 将模式名称添加到 [`RestrictAllowedSchemas`](https://gitlab.com/gitlab-org/gitlab/-/blob/master/lib/gitlab/database/query_analyzers/restrict_allowed_schemas.rb#L82)\n\n```diff\ndiff --git a/lib/gitlab/database/query_analyzers/restrict_allowed_schemas.rb b/lib/gitlab/database/query_analyzers/restrict_allowed_schemas.rb\nindex 4ae3622479f0800c0553959e132143ec9051898e..d556ec7f55adae9d46a56665ce02de782cb09f2d 100644\n--- a/lib/gitlab/database/query_analyzers/restrict_allowed_schemas.rb\n+++ b/lib/gitlab/database/query_analyzers/restrict_allowed_schemas.rb\n@@ -79,7 +79,7 @@ def restrict_to_dml_only(parsed)\n tables = self.dml_tables(parsed)\n schemas = self.dml_schemas(tables)\n \n- if (schemas - self.allowed_gitlab_schemas).any?\n+\n if (schemas - (self.allowed_gitlab_schemas << :gitlab_ci)).any?\n raise DMLAccessDeniedError, \\n "Select/DML queries (SELECT/UPDATE/DELETE) do access \'#{tables}\' (#{schemas.to_a}) " \\n "which is outside of list of allowed schemas: \'#{self.allowed_gitlab_schemas}\'. " \\n```\n\n#### 启动数据库迁移流水线\n\n创建一个包含您更改的草稿合并请求,并触发手动 `db:gitlabcom-database-testing` 任务。\n\n### 建立依赖关系\n\n在某些情况下,迁移依赖于先前排队的批量后台迁移(BBM)的完成。如果BBM仍在运行,则依赖的迁移将失败。例如:在大表上引入唯一索引可能依赖于先前排队的BBM来处理任何重复记录。\n\n已配置以下流程,以便在编写迁移时更清晰地显示依赖关系。\n\n- 排队BBM的迁移版本存储在 `batched_background_migrations` 表和BBM字典文件中。\n\n- 在每个迁移文件中添加了 `DEPENDENT_BATCHED_BACKGROUND_MIGRATIONS` 常量(默认注释)。要建立依赖关系,请添加相关BBM的 `queued_migration_version`。如果没有,请删除注释行。\n\n- 如果相关的BBM尚未完成,`Migration::UnfinishedDependencies` cop会发出警告。它通过查看BBM字典中的 `finalized_by` 键来确定它们是否已完成。\n\n示例:\n\n```ruby\n# db/post_migrate/20231113120650_queue_backfill_routes_namespace_id.rb\nclass QueueBackfillRoutesNamespaceId < Gitlab::Database::Migration[2.1]\n MIGRATION = \'BackfillRouteNamespaceId\'\n\nrestrict_gitlab_migration gitlab_schema: :gitlab_main\n ...\n ...\n\ndef up\n queue_batched_background_migration(\n MIGRATION,\n ...\n )\n end\nend\n```\n\n```ruby\n# 这取决于QueueBackfillRoutesNamespaceId BBM的最终完成\nclass AddNotNullToRoutesNamespaceId < Gitlab::Database::Migration[2.1]\n DEPENDENT_BATCHED_BACKGROUND_MIGRATIONS = ["20231113120650"]\n\ndef up\n add_not_null_constraint :routes, :namespace_id\n end\n\ndef down\n remove_not_null_constraint :routes, :namespace_id\n end\nend\n```\n\n## 管理\n\n
\n\nBBM管理通过 chatops 集成进行,仅限GitLab团队成员使用。\n\n
\n\n### 列出批量后台迁移\n\n要列出系统中的批量后台迁移,请运行以下命令:\n\n`/chatops run batched_background_migrations list`\n\n此命令支持以下选项:\n\n- 数据库选择:\n\n- `--database DATABASE_NAME`:连接到指定数据库:\n\n- `main`:使用主数据库(默认)。\n\n- `ci`:使用CI数据库。\n\n- 环境选择:\n\n- `--dev`:使用 `dev` 环境。\n\n- `--staging`:使用 `staging` 环境。\n\n- `--staging_ref`:使用 `staging_ref` 环境。\n\n- `--production` :使用 `production` 环境(默认)。\n\n- 按作业类过滤\n\n- `--job-class-name JOB_CLASS_NAME`:仅列出给定作业类的作业。\n\n- 这是背景迁移YAML定义中的 `migration_job_name`。\n\n输出示例:\n\n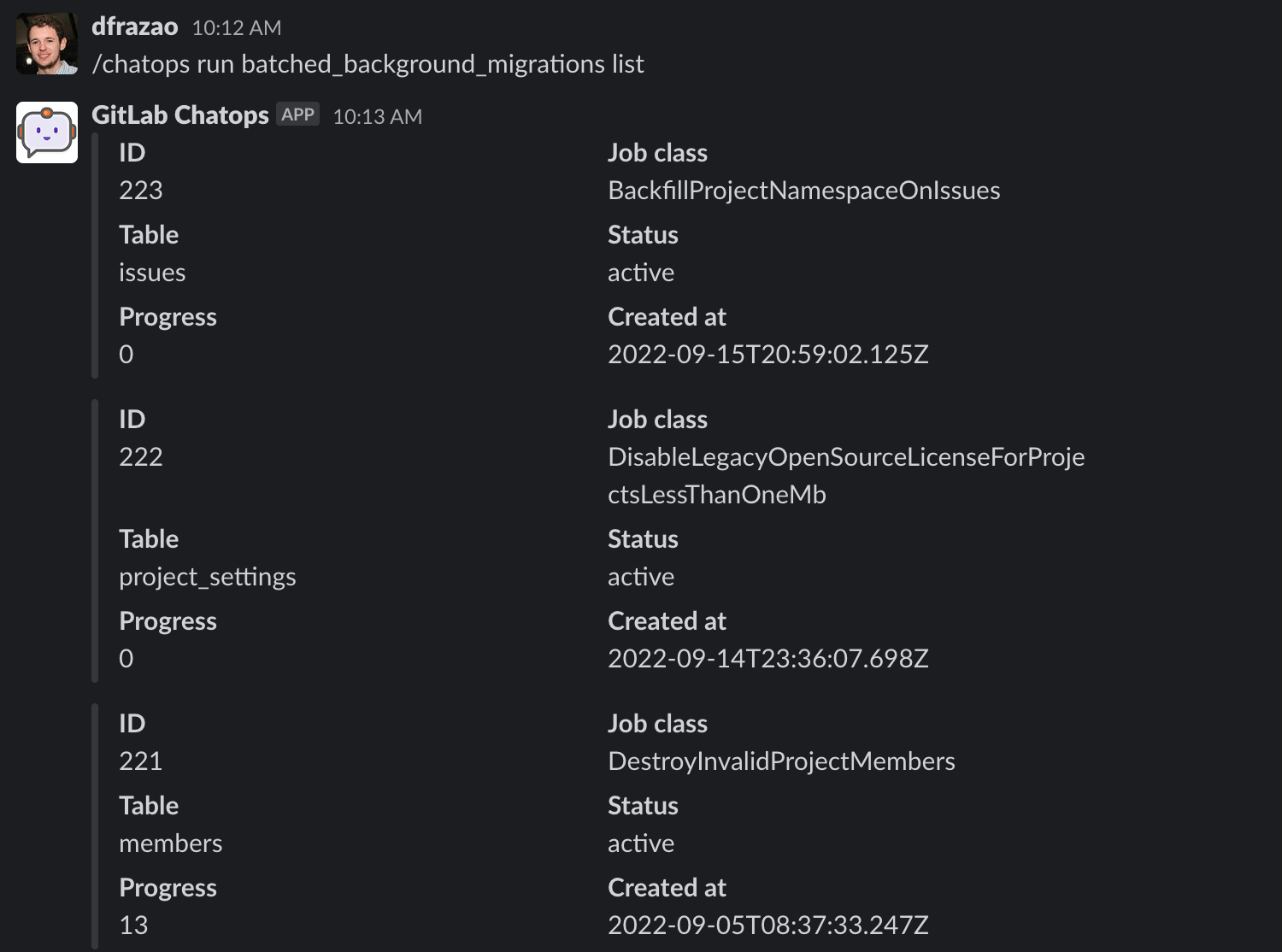\n\n
\n\nChatOps按 created_at(降序)返回20个批量后台迁移。\n\n
\n\n### 监控批量后台迁移的进度和状态\n\n要查看特定批量后台迁移的状态和进度,请运行以下命令:\n\n`/chatops run batched_background_migrations status MIGRATION_ID`\n\n此命令支持以下选项:\n\n- 数据库选择:\n\n- `--database DATABASE_NAME`:连接到指定数据库:\n\n- `main`:使用主数据库(默认)\n\n- `ci`:使用CI数据库\n\n- 环境选择:\n\n- `--dev`:使用 `dev` 环境。\n\n- `--staging`:使用 `staging` 环境。
```markdown
- `--staging_ref`:使用 `staging_ref` 环境。
- `--production`:使用 `production` 环境(默认)。

`Progress` 表示后台迁移的完成百分比。
批量后台迁移状态的定义:
- **活跃**:以下任一情况:
- 等待运行器选取
- 正在运行批处理作业
- **最终化**:正在运行批处理作业
- **失败**:批量后台迁移失败
- **完成**:所有作业已成功执行,批量后台迁移已完成
- **暂停**:对运行器不可见
- **已验证**:批量迁移通过 [`ensure_batched_background_migration_is_finished`](#finalize-a-batched-background-migration) 验证并已完成
### 暂停批量后台迁移
如果您想暂停一个批量后台迁移,您需要运行以下命令:
`/chatops run batched_background_migrations pause MIGRATION_ID`
此命令支持以下选项:
- 数据库选择:
- `--database DATABASE_NAME`:连接到指定数据库:
- `main`:使用主数据库(默认)。
- `ci`:使用 CI 数据库。
- 环境选择:
- `--dev`:使用 `dev` 环境。
- `--staging`:使用 `staging` 环境。
- `--staging_ref`:使用 `staging_ref` 环境。
- `--production`:使用 `production` 环境(默认)。
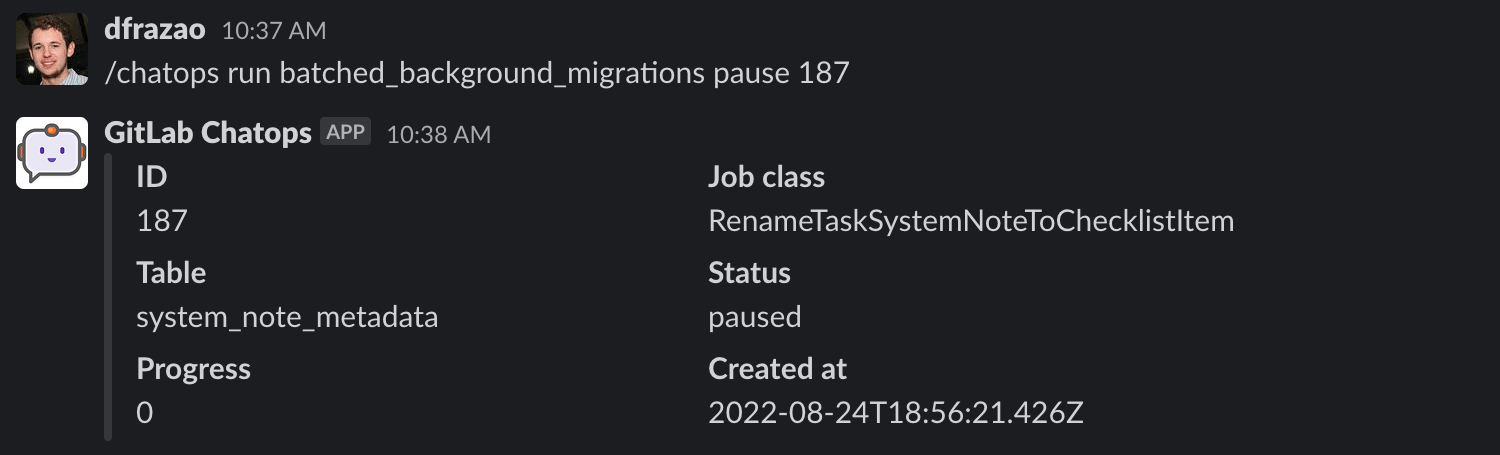
您只能暂停处于 active 状态的批量后台迁移。
### 恢复批量后台迁移
如果您想恢复一个批量后台迁移,您需要运行以下命令:
`/chatops run batched_background_migrations resume MIGRATION_ID`
此命令支持以下选项:
- 数据库选择:
- `--database DATABASE_NAME`:连接到指定数据库:
- `main`:使用主数据库(默认)。
- `ci`:使用 CI 数据库。
- 环境选择:
- `--dev`:使用 `dev` 环境。
- `--staging`:使用 `staging` 环境。
- `--staging_ref`:使用 `staging_ref` 环境。
- `--production`:使用 `production` 环境(默认)。
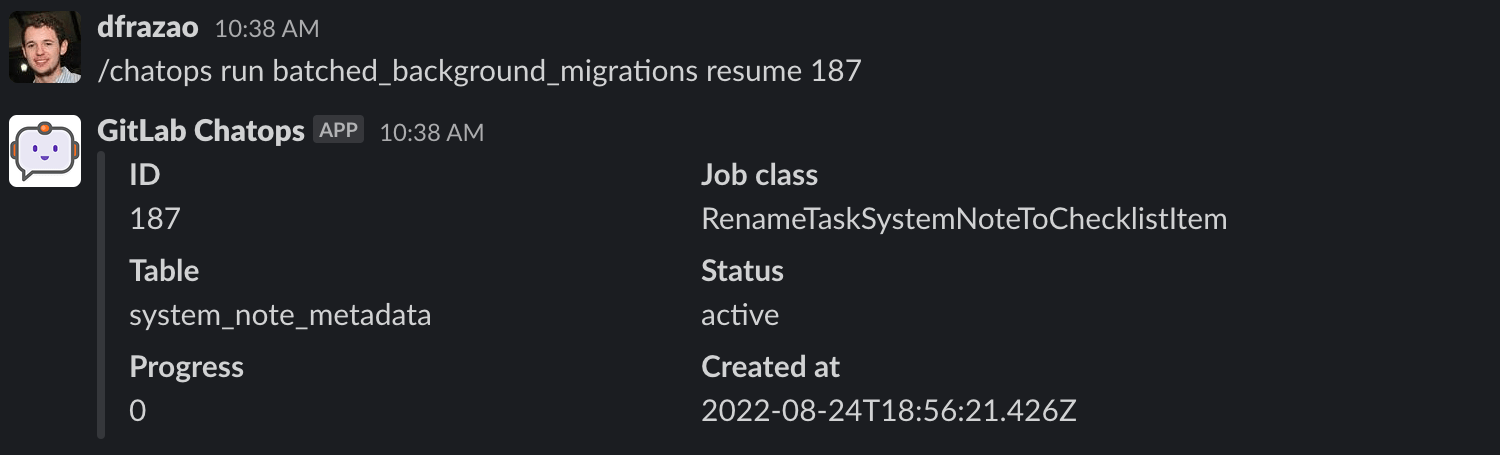
您只能恢复处于 active 状态的批量后台迁移
### 启用或禁用后台迁移
在极其有限的情况下,GitLab 管理员可以禁用以下一个或两个 [功能标志](../../administration/feature_flags/_index.md):
- `execute_background_migrations`
- `execute_batched_migrations_on_schedule`
这些标志默认启用。仅在特殊情况下限制数据库操作时才禁用它们,例如数据库主机维护。
除非您完全理解其后果,否则不要禁用这些标志中的任何一个。如果禁用了 execute_background_migrations 或 execute_batched_migrations_on_schedule 功能标志,GitLab 升级可能会失败并且可能发生数据丢失。
## 仅限 EE 功能的批量后台迁移
所有仅限 EE 功能的后台迁移类都应该存在于 GitLab FOSS 中。
为此,请为 GitLab FOSS 创建一个空类,并按照 [实现企业版功能](../ee_features.md#code-in-libgitlabbackground_migration) 指南中所述进行扩展。
使用作业参数的仅限 EE 功能的后台迁移类应该在 GitLab FOSS 类中定义它们。
需要这些定义以防止在 GitLab FOSS 上下文中调度迁移时作业参数验证失败。
您可以使用 [生成器](#generate-a-batched-background-migration) 通过在生成新的批量后台迁移时传递 `--ee-only` 标志来生成仅限 EE 的迁移脚手架。
## 调试
### 查看失败错误日志
您可以通过两种方式查看失败信息:
- 通过 GitLab 日志:
1. 运行批量后台迁移后,如果有任何作业失败,
在 [Kibana](https://log.gprd.gitlab.net/goto/4cb43f40-f861-11ec-b86b-d963a1a6788e) 中查看日志。
查看 production Sidekiq 日志并筛选:
- `json.new_state: failed`
- `json.job_class_name: <批量后台迁移作业类名>`
- `json.job_arguments: <批量后台迁移作业类参数>`
1. 查看 `json.exception_class` 和 `json.exception_message` 值以帮助
了解作业失败的原因。请记住重试机制。发生失败并不意味着任务失败。始终检查任务的最新状态。
通过数据库:
- 获取批量后台迁移的类名(
CLASS_NAME)。 - 在 PostgreSQL 控制台中执行以下查询:
SELECT migration.id, migration.job_class_name, transition_logs.exception_class, transition_logs.exception_message
FROM batched_background_migrations AS migration
INNER JOIN batched_background_migration_jobs AS jobs
ON jobs.batched_background_migration_id = migration.id
INNER JOIN batched_background_migration_job_transition_logs AS transition_logs
ON transition_logs.batched_background_migration_job_id = jobs.id
WHERE transition_logs.next_status = '2' AND migration.job_class_name = "CLASS_NAME";测试
编写测试需满足以下要求:
- 批量后台迁移的队列迁移。
- 批量后台迁移本身。
- 清理迁移。
:migration 和 schema: :latest RSpec 标签会自动设置为后台迁移规范。参考 测试 Rails 迁移 风格指南。
请注意,before 和 after RSpec 钩子会将数据库迁移至上下文。这些钩子可能导致其他批量后台迁移被调用。建议使用带有 have_received 的 spy 测试替身,而非普通测试替身,因为你在 it 块中定义的期望可能与 RSpec 钩子中调用的内容冲突。更多详情请参阅 问题 #35351。
最佳实践
- 了解你正在处理的数据量。
- 确保批量后台迁移任务是幂等的。
- 确认编写的测试不会产生误报。
- 如果迁移的数据至关重要且不能丢失,则清理迁移也必须在完成前检查数据的最终状态。
- 与数据库专家讨论相关数值。迁移可能对数据库施加比你预期更大的压力。请在预发布环境测量,或请求他人在生产环境中测量。
- 了解运行批量后台迁移所需的时间。
- 当在任务类中静默捕获异常时要谨慎。这可能导致即使在失败场景下,任务也被标记为成功。
# good
def perform
each_sub_batch do |sub_batch|
sub_batch.update_all(name: 'My Name')
end
end
# acceptable
def perform
each_sub_batch do |sub_batch|
sub_batch.update_all(name: 'My Name')
rescue Exception => error
logger.error(message: error.message, class: error.class)
raise
end
end
# bad
def perform
each_sub_batch do |sub_batch|
sub_batch.update_all(name: 'My Name')
rescue Exception => error
logger.error(message: error.message, class: self.class.name)
end
end- 如果可能,通过单个查询更新整个子批次,而不是分别更新每个模型。具体实现方式取决于场景:
- 生成
UPDATE查询,并使用FROM连接提供必要值的表(示例)。 - 生成
UPDATE查询,并使用FROM(VALUES(...))传递预先计算好的值(示例)。 - 将所有键和值传递给
ActiveRelation#update。
# good
def perform
each_sub_batch do |sub_batch|
connection.execute <<~SQL
UPDATE fork_networks
SET organization_id = projects.organization_id
FROM projects
WHERE fork_networks.id IN (#{sub_batch.pluck(:id)})
AND fork_networks.root_project_id = projects.id
AND fork_networks.organization_id IS NULL
SQL
end
end
# bad
def perform
each_sub_batch do |sub_batch|
sub_batch.each do |fork_network|
fork_network.update!(organization_id: fork_network.root_project.organization_id)
end
end
end使用 scope_to
在编写批量后台迁移类时,你可以选择定义一个 scope_to 块。该块会在确定每个批次的范围时添加额外的限定条件。
默认情况下,批次范围是通过主键索引确定的,效率很高。但是,使用 scope_to 意味着查询必须仅考虑符合给定条件的行,这可能影响性能。
考虑以下简单查询:
SELECT id FROM users WHERE id BETWEEN 1 AND 3000;此查询很快,因为 id 列已建立索引。PostgreSQL 可以使用索引仅扫描来高效返回结果。查询计划可能如下所示:
QUERY PLAN使用 users_pkey 在 users 表上的仅索引扫描(成本=0.44..307.24 行数=2751 宽度=4)(实际时间=0.016..177.028 行数=2654 循环次数=1) 索引条件:((id >= 1) AND (id <= 3000)) 堆获取次数:219 规划时间:0.183 毫秒 执行时间:177.158 毫秒
现在,让我们应用一个作用域:
```ruby
scope_to ->(relation) { relation.where(theme_id: 4) }这将产生以下查询:
SELECT id FROM users WHERE id BETWEEN 1 AND 3000 AND theme_id = 4;关联的查询计划效率较低:
查询计划
--------------------------------------------------------------------------------------------------------------------------
使用 users_pkey 在 users 表上的索引扫描(成本=0.44..3773.66 行数=10 宽度=4)(实际时间=8.047..2290.528 行数=28 循环次数=1)
索引条件:((id >= 1) AND (id <= 3000))
过滤条件:(theme_id = 4)
被过滤移除的行数:2626
规划时间:1.292 毫秒
执行时间:2290.582 毫秒在这种情况下,PostgreSQL 使用 id 的索引扫描,但在行访问后应用 theme_id 过滤器。这导致许多行在检索后被丢弃,从而降低性能,在此案例中慢了超过12倍。
何时覆盖
仅在被作用域列已建立索引时使用 scope_to,并且理想情况下,批处理查询避免过滤掉行。
良好的性能指标是查询计划中没有 Rows Removed by Filter 这一行。
让我们通过为 theme_id 列建立索引来提高性能:
CREATE INDEX idx_users_theme_id ON users (theme_id);重新运行相同查询会产生此计划:
查询计划
--------------------------------------------------------------------------------------------------------------------------------
位图堆扫描 on users (成本=691.28..706.53 行数=10 宽度=4)(实际时间=13.532..13.578 行数=28 循环次数=1)
再检查条件:((id >= 1) AND (id <= 3000) AND (theme_id = 4))
堆块:精确=28
缓冲区:共享命中=41 读取=62
I/O 时间:共享读取=0.721
-> 位图与操作 (成本=691.28..691.28 行数=10 宽度=0)(实际时间=13.509..13.511 行数=0 循环次数=1)
缓冲区:共享命中=13 读取=62
I/O 时间:共享读取=0.721
-> 位图索引扫描 on users_pkey (成本=0.00..45.95 行数=2751 宽度=0)(实际时间=0.390..0.390 行数=2654 循环次数=1)
索引条件:((id >= 1) AND (id <= 3000))
缓冲区:共享命中=10
-> 位图索引扫描 on idx_users_theme_id (成本=0.00..645.08 行数=73352 宽度=0)(实际时间=12.933..12.933 行数=69872 循环次数=1)
索引条件:(theme_id = 4)
缓冲区:共享命中=3 读取=62
I/O 时间:共享读取=0.721
规划:
缓冲区:共享命中=35 读取=1 弄脏=2
I/O 时间:共享读取=0.045
规划时间:0.514 毫秒
执行时间:13.634 毫秒总结
仅在以下情况使用 scope_to:
- 被作用域列由索引支持。
- 查询计划避免了显著的行过滤(
Rows Removed by Filter低或不存在)。 - 批处理在实际数据负载下仍保持高效。
否则,作用域会大幅降低性能。
示例
路由用例
routes 表有一个 source_type 字段用于多态关系。作为数据库重新设计的一部分,我们正在移除多态关系。工作的一步是将数据从 source_id 列迁移到新的单一外键。因为我们打算稍后删除旧行,所以不需要在后台迁移中更新它们。
- 首先使用生成器创建批处理后台迁移文件:
bundle exec rails g batched_background_migration BackfillRouteNamespaceId --table_name=routes --column_name=id --feature_category=source_code_management- 更新迁移作业(
BatchedMigrationJob的子类)以将source_id值复制到namespace_id:
class Gitlab::BackgroundMigration::BackfillRouteNamespaceId < BatchedMigrationJob
# 为了说明目的,如果我们使用本地模型,可以这样定义,使用 `ApplicationRecord` 作为基类
# class Route < ::ApplicationRecord
# self.table_name = 'routes'
# end
operation_name :update_all
feature_category :source_code_management
def perform
each_sub_batch(
batching_scope: -> (relation) { relation.where("source_type <> 'UnusedType'") }
) do |sub_batch|
sub_batch.update_all('namespace_id = source_id')
end
end
end作业类继承自 BatchedMigrationJob 以确保它们被批处理迁移框架正确处理。任何 BatchedMigrationJob 的子类都会初始化必要的参数来执行批处理,并连接到跟踪数据库。
以下是翻译后的内容,保留了所有原始格式和术语:
标题:创建数据库迁移以添加新触发器到数据库
描述:示例:
class AddTriggerToRoutesToCopySourceIdToNamespaceId < Gitlab::Database::Migration[2.1]
FUNCTION_NAME = 'example_function'
TRIGGER_NAME = 'example_trigger'
def up
execute(<<~SQL)
CREATE OR REPLACE FUNCTION #{FUNCTION_NAME}() RETURNS trigger
LANGUAGE plpgsql
AS $$
BEGIN
NEW."namespace_id" = NEW."source_id"
RETURN NEW;
END;
$$;
CREATE TRIGGER #{TRIGGER_NAME}() AFTER INSERT OR UPDATE
ON routes
FOR EACH ROW EXECUTE FUNCTION #{FUNCTION_NAME}();
SQL
end
def down
drop_trigger(TRIGGER_NAME, :routes)
drop_function(FUNCTION_NAME)
end
end标题:用所需批量大小更新已创建的部署后迁移
class QueueBackfillRoutesNamespaceId < Gitlab::Database::Migration[2.1]
MIGRATION = 'BackfillRouteNamespaceId'
BATCH_SIZE = 1000
SUB_BATCH_SIZE = 100
restrict_gitlab_migration gitlab_schema: :gitlab_main
def up
queue_batched_background_migration(
MIGRATION,
:routes,
:id,
batch_size: BATCH_SIZE,
sub_batch_size: SUB_BATCH_SIZE
)
end
def down
delete_batched_background_migration(MIGRATION, :routes, :id, [])
end
end# db/docs/batched_background_migrations/backfill_route_namespace_id.yml
---
migration_job_name: BackfillRouteNamespaceId
description: 复制路由(routes)中的 source_id 值到 namespace_id
feature_category: 源码管理
introduced_by_url: "https://mr_url"
milestone: 16.6
queued_migration_version: 20231113120650
finalized_by: # 确保此批量迁移完成的迁移版本当排队批量后台迁移时,你需要将模式限制到实际执行更改的数据库。
在此例中,我们正在更新 routes 记录,因此设置 restrict_gitlab_migration gitlab_schema: :gitlab_main。
然而,如果你需要进行 CI 数据迁移,则应设置 restrict_gitlab_migration gitlab_schema: :gitlab_ci。
部署后,我们的应用程序:
- 继续像之前一样使用数据。
- 确保现有和新数据都被迁移。
标题:添加新的部署后迁移以检查批量后台迁移是否完成,并更新 BBM 字典中的 finalized_by 属性为该迁移版本
class FinalizeBackfillRouteNamespaceId < Gitlab::Database::Migration[2.1]
disable_ddl_transaction!
restrict_gitlab_migration gitlab_schema: :gitlab_main
def up
ensure_batched_background_migration_is_finished(
job_class_name: 'BackfillRouteNamespaceId',
table_name: :routes,
column_name: :id,
job_arguments: [],
finalize: true
)
end
def down
# 无操作
end
end# db/docs/batched_background_migrations/backfill_route_namespace_id.yml
---
migration_job_name: BackfillRouteNamespaceId
description: 复制路由(routes)中的 source_id 值到 namespace_id
feature_category: 源码管理
introduced_by_url: "https://mr_url"
milestone: 16.6
queued_migration_version: 20231113120650
finalized_by: 20231115120912如果批量后台迁移未完成,系统会内联执行该批量后台迁移。
若你不希望看到此行为,需传递 finalize: false 参数。
如果应用程序不依赖数据 100% 迁移完成(例如数据仅为参考性,非关键任务),则可跳过此最终步骤。 此步骤确认迁移已完成,且所有行都已迁移。
标题:添加数据库迁移以移除触发器
class RemoveNamepaceIdTriggerFromRoutes < Gitlab::Database::Migration[2.1]
FUNCTION_NAME = 'example_function'
TRIGGER_NAME = 'example_trigger'
def up
drop_trigger(TRIGGER_NAME, :routes)
drop_function(FUNCTION_NAME)
end
def down
# 应反向执行添加触发器和函数的迁移中的 up 方法逻辑
end
end在批量迁移完成后,你可安全地依赖 routes.namespace_id 中的数据已被填充。