控制作业的运行方式
- 层级(Tier): Free, Premium, Ultimate
- 提供方式(Offering): GitLab.com, GitLab Self-Managed, GitLab Dedicated
在新的流水线开始之前,GitLab 会检查流水线配置以确定哪些作业可以在该流水线中运行。你可以使用 rules 根据变量值或流水线类型等条件来配置作业是否运行。使用作业规则时,了解如何 避免重复流水线。若要控制流水线的创建,请使用 workflow:rules。
创建必须手动运行的作业
你可以要求某个作业除非由用户启动否则不运行。这称为 手动作业。你可能希望对诸如部署到生产环境这类操作使用手动作业。
要将作业指定为手动作业,请在 .gitlab-ci.yml 文件中将 when: manual 添加到该作业中。
默认情况下,当流水线启动时,手动作业会显示为已跳过。
你可以使用 受保护分支 更严格地防止未经授权的用户运行手动部署。
被 归档 的手动作业不会运行。
手动作业的类型
手动作业可以是可选的或阻塞的。
在可选的手动作业中:
allow_failure为true,这是在rules外部定义when: manual的作业的默认设置。- 该状态不会影响整体流水线状态。即使所有手动作业都失败,流水线也可能成功。
在阻塞的手动作业中:
allow_failure为false,这是在rules内部定义when: manual的作业的默认设置。- 流水线会在定义该作业的阶段停止。若要让流水线继续运行,请 运行手动作业。
- 在启用了 流水线必须成功 的项目中,合并请求无法与阻塞的流水线合并。
- 流水线会显示 阻塞 状态。
在使用带有 trigger:strategy 的触发式流水线中使用手动作业时,手动作业的类型可能会影响流水线运行期间触发作业的状态。
运行手动作业
要运行手动作业,你必须拥有合并到指定分支的权限:
- 进入流水线、作业、环境 或部署视图。
- 在手动作业旁边,选择 运行 ( )。
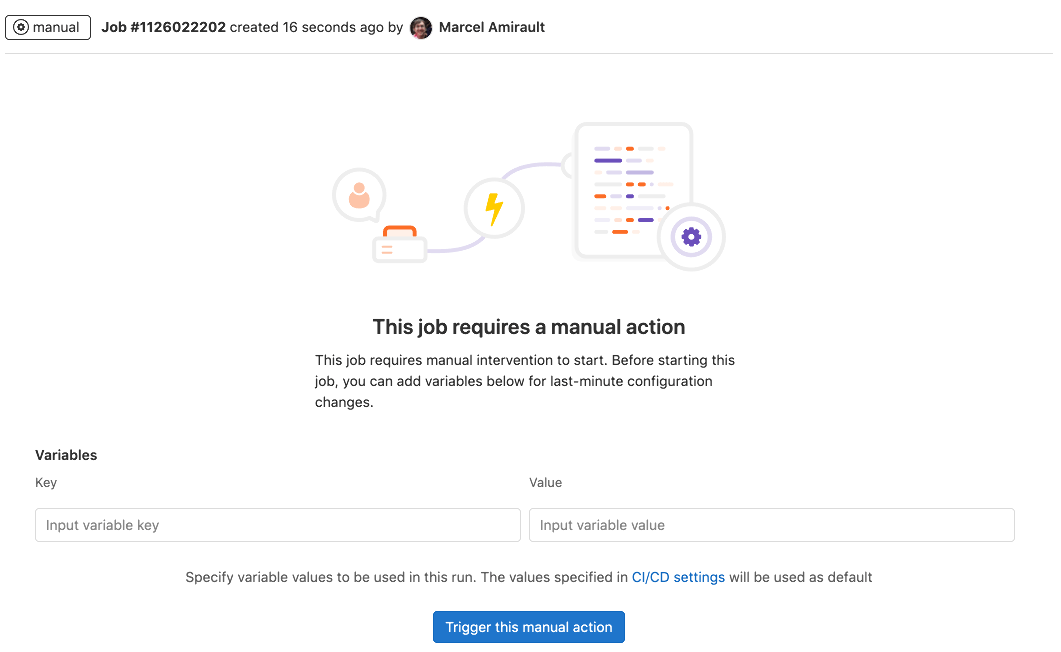
运行手动作业时指定变量
运行手动作业时可以提供额外的作业特定变量。
你可以在要运行并带有额外变量的手动作业的作业页面上执行此操作。要访问此页面,请在流水线视图中选择手动作业的 名称,而不是 运行 ( )。
当你想要修改使用 CI/CD 变量 的作业的执行时,在此处定义 CI/CD 变量。
如果你添加了已在 CI/CD 设置或 .gitlab-ci.yml 文件中定义的变量,则该 变量会被新值覆盖。通过此过程覆盖的任何变量都会被 展开,而不会被 屏蔽。
要求手动作业确认
使用 manual_confirmation 与 when: manual 结合,要求手动作业确认。这有助于防止意外部署或删除,例如那些部署到生产环境的敏感作业。
当你触发作业时,必须在运行前确认操作。
保护手动作业
- 层级:高级版,旗舰版
- 提供方式:GitLab.com,GitLab 自托管,GitLab 专属版
使用受保护的环境来定义一组获授权运行手动作业的用户列表。你可以仅授权关联到受保护环境的用户触发手动作业,这能:
- 更精确地限制谁能部署到环境中。
- 阻止流水线运行,直至获得批准的用户“批准”它。
要保护手动作业:
-
向作业添加一个
environment。例如:deploy_prod: stage: deploy script: - echo "Deploy to production server" environment: name: production url: https://example.com when: manual rules: - if: $CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH -
在受保护环境设置中,选择环境(本例中为
production),并将获授权触发该手动作业的用户、角色或组添加到允许部署列表。只有此列表中的用户才能触发该手动作业,而始终能够使用受保护环境的GitLab管理员除外。
你可以将受保护的环境与阻塞型手动作业配合使用,以拥有一份获授权批准后续流水线阶段的用户列表。向受保护的手动作业添加 allow_failure: false,这样只有在获授权用户触发了该手动作业后,流水线的后续阶段才会运行。
延迟执行作业
使用when: delayed在等待一段时间后执行脚本,或者如果你希望避免作业立即进入 pending 状态。
你可以使用 start_in 关键字设置时间段。start_in 的值是以秒为单位的时间间隔,除非提供了时间单位。最小值为1秒,最大值为1周。有效的示例如下:
'5'(无单位的数值必须用单引号括起来)5 seconds30 minutes1 day1 week
当一个阶段包含延迟作业时,流水线不会继续推进,直到该延迟作业完成。你可以使用此关键字在不同阶段之间插入延迟。
延迟作业的计时器在前一阶段完成后立即启动。与其他类型的作业类似,除非前一阶段通过,否则延迟作业的计时器不会启动。
以下示例创建了一个名为 timed rollout 10% 的作业,它在上一阶段完成后30分钟执行:
timed rollout 10%:
stage: deploy
script: echo '正在推出10%...'
when: delayed
start_in: 30 minutes
environment: production若要停止延迟作业的活动计时器,请选择取消调度( )。该作业将无法再自动调度运行。不过,你可以手动执行该作业。
若要手动启动延迟作业,请先选择取消调度( )以停止延迟计时器,然后选择运行( )。不久后,GitLab Runner 将启动该作业。
已归档的流水线中的延迟作业不会运行。
并行化大型作业
要将大型作业拆分为多个并行运行的小型作业,请在你的 .gitlab-ci.yml 文件中使用parallel关键字。
不同的语言和测试套件有不同的启用并行化的方法。例如,使用Semaphore Test Boosters和RSpec并行运行Ruby测试:
# Gemfile
source 'https://rubygems.org'
gem 'rspec'
gem 'semaphore_test_boosters'test:
parallel: 3
script:
- bundle
- bundle exec rspec_booster --job $CI_NODE_INDEX/$CI_NODE_TOTAL之后你可以前往新流水线构建的作业标签页,看到你的RSpec作业被拆分为三个独立的作业。
Test Boosters 会向作者报告使用统计信息。
运行一维矩阵的并行作业
若要在单个流水线中多次并行运行某个作业,且每个作业实例使用不同的变量值,请使用parallel:matrix关键字:
deploystacks:
stage: deploy
script:
- bin/deploy
parallel:
matrix:
- PROVIDER: [aws, ovh, gcp, vultr]
environment: production/$PROVIDER运行一组并行的触发器作业矩阵
你可以在单个流水线中多次并行运行一个触发器作业,但每个作业实例使用不同的变量值。
deploystacks:
stage: deploy
trigger:
include: path/to/child-pipeline.yml
parallel:
matrix:
- PROVIDER: aws
STACK: [monitoring, app1]
- PROVIDER: ovh
STACK: [monitoring, backup]
- PROVIDER: [gcp, vultr]
STACK: [data]此示例会生成6个并行的 deploystacks 触发器作业,每个作业都有不同的 PROVIDER 和 STACK 值,它们会用这些变量创建6个不同的子流水线。
deploystacks: [aws, monitoring]
deploystacks: [aws, app1]
deploystacks: [ovh, monitoring]
deploystacks: [ovh, backup]
deploystacks: [gcp, data]
deploystacks: [vultr, data]为每个并行矩阵作业选择不同的运行器标签
你可以使用 parallel: matrix 中定义的变量与 tags 关键字结合,实现动态运行器选择:
deploystacks:
stage: deploy
script:
- bin/deploy
parallel:
matrix:
- PROVIDER: aws
STACK: [monitoring, app1]
- PROVIDER: gcp
STACK: [data]
tags:
- ${PROVIDER}-${STACK}
environment: $PROVIDER/$STACK从 parallel:matrix 作业获取制品
你可以通过 dependencies 关键字,从一个由 parallel:matrix 创建的作业中获取制品。使用 dependencies 时,需以字符串形式提供作业名,格式如下:
<job_name> [<matrix argument 1>, <matrix argument 2>, ... <matrix argument N>]例如,若要从 RUBY_VERSION 为 2.7 且 PROVIDER 为 aws 的作业中获取制品:
ruby:
image: ruby:${RUBY_VERSION}
parallel:
matrix:
- RUBY_VERSION: ["2.5", "2.6", "2.7", "3.0", "3.1"]
PROVIDER: [aws, gcp]
script: bundle install
deploy:
image: ruby:2.7
stage: deploy
dependencies:
- "ruby: [2.7, aws]"
script: echo hello
environment: productiondependencies 条目周围的引号是必需的。
使用 needs 指定并行化作业,配合多个并行化作业
你可以使用 needs:parallel:matrix 中定义的变量,配合多个并行化作业。
例如:
linux:build:
stage: build
script: echo "Building linux..."
parallel:
matrix:
- PROVIDER: aws
STACK:
- monitoring
- app1
- app2
mac:build:
stage: build
script: echo "Building mac..."
parallel:
matrix:
- PROVIDER: [gcp, vultr]
STACK: [data, processing]
linux:rspec:
stage: test
needs:
- job: linux:build
parallel:
matrix:
- PROVIDER: aws
STACK: app1
script: echo "Running rspec on linux..."
mac:rspec:
stage: test
needs:
- job: mac:build
parallel:
matrix:
- PROVIDER: [gcp, vultr]
STACK: [data]
script: echo "Running rspec on mac..."
production:
stage: deploy
script: echo "Running production..."
environment: production此示例会生成多个作业。并行作业各自有不同的 PROVIDER 和 STACK 值。
- 3 个并行的
linux:build作业:linux:build: [aws, monitoring]linux:build: [aws, app1]linux:build: [aws, app2]
- 4 个并行的
mac:build作业:mac:build: [gcp, data]mac:build: [gcp, processing]mac:build: [vultr, data]mac:build: [vultr, processing]
- 一个
linux:rspec作业。 - 一个
production作业。
作业有三种执行路径:
- Linux 路径:当
linux:build: [aws, app1]作业完成时,linux:rspec作业立即运行,无需等待mac:build完成。 - macOS 路径:当
mac:build: [gcp, data]和mac:build: [vultr, data]作业完成后,mac:rspec作业立即运行,无需等待linux:build完成。 production作业在所有前置作业完成后立即运行。
指定并行作业之间的依赖关系
你可以使用needs:parallel:matrix进一步定义每个并行矩阵作业的顺序。
例如:
build_job:
stage: build
script:
# 确保除 build_job [1, A] 以外的其他并行作业运行更长时间
- '[[ "$VERSION" == "1" && "$MODE" == "A" ]] || sleep 30'
- echo build $VERSION $MODE
parallel:
matrix:
- VERSION: [1,2]
MODE: [A, B]
deploy_job:
stage: deploy
script: echo deploy $VERSION $MODE
parallel:
matrix:
- VERSION: [3,4]
MODE: [C, D]
'deploy_job: [3, D]':
stage: deploy
script: echo something
needs:
- 'build_job: [1, A]'此示例会生成多个作业。每个并行作业的 VERSION 和 MODE 值不同。
- 4 个并行的
build_job作业:build_job: [1, A]build_job: [1, B]build_job: [2, A]build_job: [2, B]
- 4 个并行的
deploy_job作业:deploy_job: [3, C]deploy_job: [3, D]deploy_job: [4, C]deploy_job: [4, D]
deploy_job: [3, D] 作业会在 build_job: [1, A] 作业完成后立即运行,无需等待其他 build_job 作业完成。
故障排除
运行手动作业时的用户分配不一致问题
在某些极端情况下,运行手动作业的用户未被分配为依赖于该手动作业的后续作业的用户。
如果你需要对依赖于手动作业的作业的用户分配有严格的安全要求,你应该保护手动作业。