解决 Geo 同步和验证错误
- Tier: Premium, Ultimate
- Offering: GitLab Self-Managed
如果您在 管理 > Geo > 站点 或 同步状态 Rake 任务 中发现复制或验证失败,可以尝试通过以下通用步骤解决这些问题:
- Geo 会自动重试失败。如果失败是新出现的且数量较少,或者您怀疑根本原因已经解决,可以等待观察失败是否消失。
- 如果失败持续了很长时间,已经进行了多次重试,并且自动重试的间隔时间已根据失败类型增加到最多 4 小时。如果您怀疑根本原因已经解决,可以手动重试复制或验证以避免等待。
- 如果失败仍然存在,请使用以下部分尝试解决。
手动重试复制或验证
在次要 Geo 站点的 Rails 控制台 中,您可以:
重新同步和重新验证单个组件
在次要站点,访问管理 > Geo > 复制,强制重新同步或重新验证单个项目。
但是,如果这不起作用,您可以使用 Rails 控制台执行相同的操作。以下部分描述如何使用 Rails 控制台 中的内部应用程序命令来同步或验证单个记录的复制或验证。
获取 Replicator 实例
如果未在正确条件下运行,更改数据的命令可能会造成损坏。始终先在测试环境中运行命令,并准备好备份实例以进行恢复。
在执行任何同步或验证操作之前,您需要获取一个 Replicator 实例。
首先,根据您想要执行的操作,在主或次要站点启动 Rails 控制台会话。
主站点:
- 您可以校验资源的校验和
次要站点:
- 您可以同步资源
- 您可以校验资源的校验和,并将其与主站点的校验和进行比较
接下来,运行以下代码片段之一来获取 Replicator 实例。
给定模型记录的 ID
- 将
123替换为实际 ID。 - 将
Packages::PackageFile替换为任何 Geo 数据类型模型类。
model_record = Packages::PackageFile.find_by(id: 123)
replicator = model_record.replicator给定注册表记录的 ID
- 将
432替换为实际 ID。注册表记录可能与它跟踪的模型记录具有相同的 ID 值,也可能不同。 - 将
Geo::PackageFileRegistry替换为任何 Geo 注册表类。
在次要 Geo 站点中:
registry_record = Geo::PackageFileRegistry.find_by(id: 432)
replicator = registry_record.replicator给定注册表记录 last_sync_failure 中的错误消息
- 将
Geo::PackageFileRegistry替换为任何 Geo 注册表类。 - 将
error message here替换为实际错误消息。
registry = Geo::PackageFileRegistry.find_by("last_sync_failure LIKE '%error message here%'")
replicator = registry.replicator给定注册表记录 verification_failure 中的错误消息
- 将
Geo::PackageFileRegistry替换为任何 Geo 注册表类。 - 将
error message here替换为实际错误消息。
registry = Geo::PackageFileRegistry.find_by("verification_failure LIKE '%error message here%'")
replicator = registry.replicator使用 Replicator 实例执行操作
当您将 Replicator 实例存储在 replicator 变量中后,您可以执行许多操作:
在控制台中同步
此代码片段仅在次要站点中有效。
这会在控制台中同步执行同步代码,因此您可以观察同步资源需要多长时间,或查看完整的错误回溯。
replicator.sync或者,使控制台的日志级别比配置的日志级别更详细,然后执行同步:
Rails.logger.level = :debug在控制台中校验或验证
此代码片段在任何主或次要站点中都有效。
在主站点中,它会校验资源并将结果存储在主 GitLab 数据库中。在次要站点中,它会校验资源,将其与主 GitLab 数据库(由主站点生成)中的校验和进行比较,并将结果存储在 Geo 跟踪数据库中。
这会在控制台中同步执行校验和验证代码,因此您可以观察需要多长时间,或查看完整的错误回溯。
replicator.verify在 Sidekiq 作业中同步
此代码片段仅在次要站点中有效。
它会将作业排队给 Sidekiq 以执行资源的sync。
replicator.enqueue_sync在 Sidekiq 作业中验证
此代码片段在任何主或次要站点中都有效。
它会将作业排队给 Sidekiq 以执行资源的校验或验证。
replicator.verify_async获取模型记录
此代码片段在任何主或次要站点中都有效。
replicator.model_record获取注册表记录
此代码片段仅在次要站点中有效,因为注册表表存储在 Geo 跟踪数据库中。
replicator.registryGeo 数据类型模型类
Geo 数据类型是特定类别的数据,由一个或多个 GitLab 功能需要存储相关数据,并由 Geo 复制到次要站点。
- Blob 类型:
Ci::JobArtifactCi::PipelineArtifactCi::SecureFileLfsObjectMergeRequestDiffPackages::PackageFilePagesDeploymentTerraform::StateVersionUploadDependencyProxy::ManifestDependencyProxy::Blob
- Git 仓库类型:
DesignManagement::RepositoryProjectRepositoryProjectWikiRepositorySnippetRepositoryGroupWikiRepository
- 其他类型:
ContainerRepository
主要的类类型是注册表(Registry)、模型(Model)和复制器(Replicator)。如果您拥有其中任何一个类的实例,就可以获取其他类。注册表和模型主要管理 PostgreSQL 数据库状态。复制器知道如何复制或验证非 PostgreSQL 数据(文件/Git 仓库/容器仓库)。
Geo 注册表类
在 GitLab Geo 的上下文中,注册表记录指的是 Geo 跟踪数据库中的注册表表。每条记录跟踪主 GitLab 数据库中的单个可复制对象,例如 LFS 文件或项目 Git 仓库。与可查询的 Geo 注册表表对应的 Rails 模型有:
- Blob 类型:
Geo::CiSecureFileRegistryGeo::DependencyProxyBlobRegistryGeo::DependencyProxyManifestRegistryGeo::JobArtifactRegistryGeo::LfsObjectRegistryGeo::MergeRequestDiffRegistryGeo::PackageFileRegistryGeo::PagesDeploymentRegistryGeo::PipelineArtifactRegistryGeo::ProjectWikiRepositoryRegistryGeo::SnippetRepositoryRegistryGeo::TerraformStateVersionRegistryGeo::UploadRegistry
- Git 仓库类型:
Geo::DesignManagementRepositoryRegistryGeo::ProjectRepositoryRegistryGeo::ProjectWikiRepositoryRegistryGeo::SnippetRepositoryRegistryGeo::GroupWikiRepositoryRegistry
- 其他类型:
Geo::ContainerRepositoryRegistry
重新同步和重新验证多个组件
如果未在正确条件下运行,更改数据的命令可能会造成损坏。始终先在测试环境中运行命令,并准备好备份实例以进行恢复。
以下部分描述如何使用 Rails 控制台 中的内部应用程序命令来执行批量复制或验证。
重新同步一个组件的所有资源
您可以从 UI 安排一个组件的所有资源的完整重新同步:
- 在左侧边栏底部,选择管理。
- 选择Geo > 站点。
- 在复制详情下,选择所需的组件。
- 选择重新同步所有。
或者,在次要 Geo 站点上启动 Rails 控制台会话以收集更多信息,或使用下面的代码片段手动执行这些操作。
如果未在正确条件下运行,更改数据的命令可能会造成损坏。始终先在测试环境中运行命令,并准备好备份实例以进行恢复。
同步一个组件中所有同步失败的资源
以下脚本:
- 遍历所有失败的仓库。
- 显示 Geo 同步和验证元数据,包括上次失败的原因。
- 尝试重新同步仓库。
- 报告是否发生失败以及原因。
- 可能需要一些时间才能完成。每个仓库检查必须完成才能报告结果。如果您的会话超时,请采取措施使进程继续运行,例如启动
screen会话,或使用 Rails runner 和nohup运行它。
Geo::ProjectRepositoryRegistry.failed.find_each do |registry|
begin
puts "ID: #{registry.id}, Project ID: #{registry.project_id}, Last Sync Failure: '#{registry.last_sync_failure}'"
registry.replicator.sync
puts "Sync initiated for registry ID: #{registry.id}"
rescue => e
puts "ID: #{registry.id}, Project ID: #{registry.project_id}, Failed: '#{e}'", e.backtrace.join("\n")
end
end; nil在所有站点上重新验证一个组件
如果主站点的校验和有问题,您需要让主站点重新计算校验和。这样就实现了"完全重新验证",因为在主站点上重新计算每个校验和后,会生成事件传播到所有次要站点,导致它们重新计算校验和并比较值。任何不匹配都会将注册表标记为 sync failed,从而安排同步重试。
UI 不提供按钮来进行完全重新验证。您可以通过在管理 > Geo > 节点 > 编辑中将主站点的 重新验证间隔 设置为 1(天)来模拟此操作。然后,主站点将重新计算任何超过 1 天前校验过的资源的校验和。
或者,您可以手动执行此操作:
-
SSH 到主站点上的 GitLab Rails 节点。
-
打开 Rails 控制台。
-
将
Upload替换为任何 Geo 数据类型模型类,将所有资源标记为等待验证:Upload.verification_state_table_class.each_batch do |relation| relation.update_all(verification_state: 0) end
在主站点上重新验证所有校验失败的资源
系统会自动重新验证在主站点上校验失败的所有资源,但它使用渐进式退避方案来避免失败数量过多。
或者,例如,如果您已完成尝试干预,可以手动触发重新验证:
-
SSH 到主站点上的 GitLab Rails 节点。
-
打开 Rails 控制台。
-
将
Upload替换为任何 Geo 数据类型模型类,将所有资源标记为等待验证:Upload.verification_state_table_class.where(verification_state: 3).each_batch do |relation| relation.update_all(verification_state: 0) end
在一个次要站点上重新验证一个组件
如果您认为主站点的校验和是正确的,可以从 UI 安排在一个次要站点上重新验证一个组件:
- 在左侧边栏底部,选择管理。
- 选择Geo > 站点。
- 在复制详情下,选择所需的组件。
- 选择重新验证所有。
错误
消息:主站点上的文件丢失
在首次设置次要 Geo 站点时,同步失败主站点上的文件丢失很常见,这是由主站点上的数据不一致引起的。
在操作 GitLab 时,由于系统或人为错误,可能会发生数据不一致和文件丢失。例如,实例管理员手动删除本地文件系统上的多个工件。此类更改未正确传播到数据库,导致不一致。这些不一致仍然存在并可能造成摩擦。Geo 次要站点可能会继续尝试复制那些文件,因为它们仍然在数据库中被引用,但已不再存在。
如果是最近从本地存储迁移到对象存储,请参阅专门的对象存储故障排除部分。
识别不一致
当存在缺失文件或不一致时,您可能会在 geo.log 中遇到如下条目。请注意 "primary_missing_file" : true 字段:
{
"bytes_downloaded" : 0,
"class" : "Geo::BlobDownloadService",
"correlation_id" : "01JT69C1ECRBEMZHA60E5SAX8E",
"download_success" : false,
"download_time_s" : 0.196,
"gitlab_host" : "gitlab.example.com",
"mark_as_synced" : false,
"message" : "Blob download",
"model_record_id" : 55,
"primary_missing_file" : true,
"reason" : "Not Found",
"replicable_name" : "upload",
"severity" : "WARN",
"status_code" : 404,
"time" : "2025-05-01T16:02:44.836Z",
"url" : "http://gitlab.example.com/api/v4/geo/retrieve/upload/55"
}相同的错误也会反映在 UI 中,在管理 > Geo > 站点下查看特定可复制对象的同步状态时。在此场景中,特定的上传文件缺失:

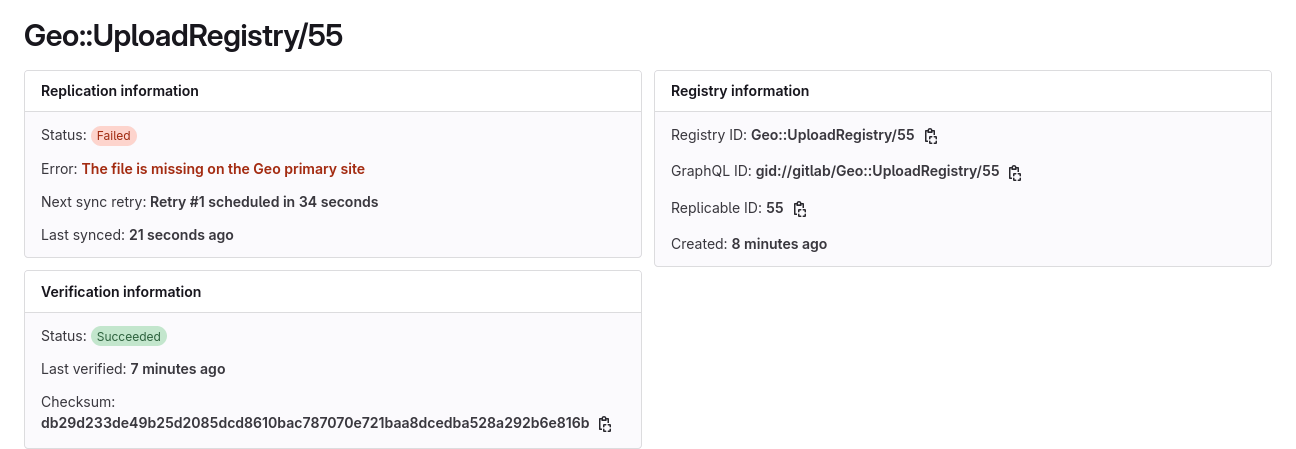
清理不一致
在发出任何删除命令之前,请确保手头有最新且可用的备份。
要删除这些错误,首先确定哪些特定资源受到影响。然后,运行适当的 destroy 命令以确保删除传播到所有 Geo 站点及其数据库。基于前面的场景,一个上传导致这些错误,下面以此为例。
-
将识别的不一致映射到相应的 Geo 模型类名称。下一步需要类名。在此场景中,对于上传对应
Upload。 -
在Geo 主站点上启动 Rails 控制台。
-
根据上一步的 Geo 模型类,查询所有因文件丢失而验证失败的资源。调整或删除
limit(20)以显示更多结果。观察列出的资源是否与 UI 中显示的失败资源匹配:Upload.verification_failed.where("verification_failure like '%File is not checksummable%'").limit(20) => #<Upload:0x00007b362bb6c4e8 id: 55, size: 13346, path: "503d99159e2aa8a3ac23602058cfdf58/openbao.png", checksum: "db29d233de49b25d2085dcd8610bac787070e721baa8dcedba528a292b6e816b", model_id: 1, model_type: "Project", uploader: "FileUploader", created_at: Thu, 01 May 2025 15:54:10.549178000 UTC +00:00, store: 1, mount_point: nil, secret: "[FILTERED]", version: 2, uploaded_by_user_id: 1, organization_id: nil, namespace_id: nil, project_id: 1, verification_checksum: nil> -
可选地,使用受影响资源的
id确定它们是否仍然需要:Upload.find(55) => #<Upload:0x00007b362bb6c4e8 id: 55, size: 13346, path: "503d99159e2aa8a3ac23602058cfdf58/openbao.png", checksum: "db29d233de49b25d2085dcd8610bac787070e721baa8dcedba528a292b6e816b", model_id: 1, model_type: "Project", uploader: "FileUploader", created_at: Thu, 01 May 2025 15:54:10.549178000 UTC +00:00, store: 1, mount_point: nil, secret: "[FILTERED]", version: 2, uploaded_by_user_id: 1, organization_id: nil, namespace_id: nil, project_id: 1, verification_checksum: nil>- 如果您确定需要恢复受影响的资源,则可以探索以下选项(非详尽)来恢复它们:
- 检查次要站点是否有该对象,并手动复制到主站点。
- 查看旧备份并手动将对象复制回主站点。
- 抽查一些,以确定删除记录可能没问题,例如,如果它们都是非常旧的工件,那么它们可能不是关键数据。
- 如果您确定需要恢复受影响的资源,则可以探索以下选项(非详尽)来恢复它们:
-
使用已识别资源的
id通过destroy单独或批量删除它们。确保使用适当的 Geo 模型类名称。-
删除单个资源:
Upload.find(55).destroy -
删除所有受影响的资源:
def destroy_uploads_not_checksummable uploads = Upload.verification_failed.where("verification_failure like '%File is not checksummable%'");1 puts "Found #{uploads.count} resources that failed verification with 'File is not checksummable'." puts "Enter 'y' to continue: " prompt = STDIN.gets.chomp if prompt != 'y' puts "Exiting without action..." return end puts "Destroying all..." uploads.destroy_all end destroy_uploads_not_checksummable
-
对所有受影响的资源和 Geo 数据类型重复这些步骤。
消息:"验证期间出错","error":"文件不可校验"
错误 "验证期间出错","error":"文件不可校验" 是由主站点上的不一致引起的。请按照主站点上的文件丢失中的说明操作。
主 Geo 站点上上传验证失败
如果某些上传在主 Geo 站点上的验证失败,verification_checksum = nil 且 verification_failure 包含 验证期间出错:未定义的方法 'underscore' for NilClass:Class 或 拥有此上传的模型缺失。,这是由于孤立的上传引起的。拥有上传的父记录(上传的"模型")以某种方式被删除,但上传记录仍然存在。这通常是由于应用程序中的错误引起的,在实现批量删除"模型"时忘记批量删除其关联的上传记录。因此,这些验证失败不是验证失败,而是 PostgreSQL 中错误数据的结果。
您可以在主 Geo 站点的 geo.log 文件中找到这些错误。
要确认模型记录是否缺失,可以在主 Geo 站点上运行 Rake 任务:
sudo gitlab-rake gitlab:uploads:check您可以通过在主 Geo 站点上运行以下脚本来删除这些上传记录以消除这些失败:
def delete_orphaned_uploads(dry_run: true)
if dry_run
p "This is a dry run. Upload rows will only be printed."
else
p "This is NOT A DRY RUN! Upload rows will be deleted from the DB!"
end
subquery = Geo::UploadState.where("(verification_failure LIKE 'Error during verification: The model which owns this Upload is missing.%' OR verification_failure = 'Error during verification: undefined method `underscore'' for NilClass:Class') AND verification_checksum IS NULL")
uploads = Upload.where(upload_state: subquery)
p "Found #{uploads.count} uploads with a model that does not exist"
uploads_deleted = 0
begin
uploads.each do |upload|
if dry_run
p upload
else
uploads_deleted=uploads_deleted + 1
p upload.destroy!
end
rescue => e
puts "checking upload #{upload.id} failed with #{e.message}"
end
end
p "#{uploads_deleted} remote objects were destroyed." unless dry_run
end前面的脚本定义了一个名为 delete_orphaned_uploads 的方法,您可以这样调用它进行试运行:
delete_orphaned_uploads(dry_run: true)而实际删除孤立的上传行:
delete_orphaned_uploads(dry_run: false)错误:同步仓库错误:13:fatal: 无法读取用户名
last_sync_failure 错误
同步仓库错误:13:fatal: 无法读取 'https://gitlab.example.com' 的用户名:终端提示已禁用
表示在 Geo 克隆或获取请求期间 JWT 身份验证失败。
首先,检查系统时钟是否同步。运行健康检查 Rake 任务,或手动检查次要站点上的所有 Sidekiq 节点和主站点上的所有 Puma 节点上的 date 是否相同。
如果系统时钟已同步,则 JWT 令牌可能在 Git fetch 在其两个单独的 HTTP 请求之间执行计算时过期。请参阅问题 464101,该问题存在于所有 GitLab 版本中,直到在 GitLab 17.1.0、17.0.5 和 16.11.7 中修复。
要验证您是否遇到此问题:
-
在次要站点上的 Rails 控制台 中修补代码,将令牌的有效期从 1 分钟增加到 10 分钟。在次要站点上的 Rails 控制台中运行:
module Gitlab; module Geo; class BaseRequest private def geo_auth_token(message) signed_data = Gitlab::Geo::SignedData.new(geo_node: requesting_node, validity_period: 10.minutes).sign_and_encode_data(message) "#{GITLAB_GEO_AUTH_TOKEN_TYPE} #{signed_data}" end end;end;end -
在同一个 Rails 控制台中,重新同步受影响的项目:
Project.find_by_full_path('<mygroup/mysubgroup/myproject>').replicator.resync -
查看同步状态:
Project.find_by_full_path('<mygroup/mysubgroup/myproject>').replicator.registry -
如果
last_sync_failure不再包含错误fatal: could not read Username,那么您遇到了此问题。状态现在应该是2,这意味着已同步。如果是这样,您应该升级到包含修复的 GitLab 版本。您可能还希望对问题 466681进行投票或评论,这将降低此问题的严重性。
要解决此问题,您必须在次要站点的所有 Sidekiq 节点上热修补以延长 JWT 过期时间:
-
编辑
/opt/gitlab/embedded/service/gitlab-rails/ee/lib/gitlab/geo/signed_data.rb。 -
找到
Gitlab::Geo::SignedData.new(geo_node: requesting_node)并添加, validity_period: 10.minutes:- Gitlab::Geo::SignedData.new(geo_node: requesting_node) + Gitlab::Geo::SignedData.new(geo_node: requesting_node, validity_period: 10.minutes) -
重启 Sidekiq:
sudo gitlab-ctl restart sidekiq -
除非您升级到包含修复的版本,否则每次 GitLab 升级后都必须重复此解决方法。
错误:同步仓库错误:13:创建仓库:克隆仓库:退出状态 128
您可能会看到此错误用于未成功同步的项目。
仓库创建期间的退出代码 128 表示 Git 在克隆时遇到致命错误。这可能是由于仓库损坏、网络问题、身份验证问题、资源限制或项目没有关联的 Git 仓库引起的。有关此类失败具体原因的更多详细信息可以在 Gitaly 日志中找到。
当不确定从哪里开始时,通过在命令行上手动执行 git fsck 命令在主站点上对源仓库进行完整性检查。
错误:在恰好 3 小时处出现 fetch remote: signal: terminated: context deadline exceeded
如果 Git fetch 在同步 Git 仓库时恰好三小时失败:
-
编辑
/etc/gitlab/gitlab.rb以将 Git 超时时间从默认的 10800 秒增加:# Git 超时时间(秒) gitlab_rails['gitlab_shell_git_timeout'] = 21600 -
重新配置 GitLab:
sudo gitlab-ctl reconfigure
在次要站点上配置注册表复制时出现 无法打开到 localhost:5000 的 TCP 连接 错误
在次要站点上配置容器注册表复制时,您可能会遇到以下错误:
无法打开到 localhost:5000 的 TCP 连接(连接被拒绝 - connect(2) 为 "localhost" 端口 5000)如果容器注册表未在次要站点上启用,就会发生这种情况。要修复它,检查容器注册表是否在次要站点上启用。如果禁用了 Let’s Encrypt 集成,容器注册表也会被禁用,您必须手动配置。
消息:同步失败 - 同步仓库错误
如果大型仓库受此问题影响, 它们的重新同步可能需要很长时间,并对您的 Geo 站点、存储和网络系统造成显著负载。
以下错误消息表示同步仓库时的一致性检查错误:
同步失败 - 同步仓库 [..] fatal: 压缩对象中 fsck 错误几个问题可能会触发此错误。例如,电子邮件地址问题:
同步仓库错误:13:fetch remote: "error: object <SHA>: badEmail: 无效的作者/提交者行 - 错误的电子邮件
fatal: 压缩对象中 fsck 错误
fatal: fetch-pack: 无效的 index-pack 输出另一个可能触发此错误的问题是 object <SHA>: hasDotgit: 包含 '.git'。检查具体错误,因为您可能在所有仓库中有多个问题。
第二个同步错误也可能由仓库检查问题引起:
同步仓库错误:13:收到错误代码为 2 的 RST_STREAM。这些错误可以通过立即同步所有失败的仓库观察到。
删除导致一致性错误的格式错误对象涉及重写仓库历史,这通常不是选项。
要忽略这些一致性检查,在次要 Geo 站点上重新配置 Gitaly 以忽略这些 git fsck 问题。以下配置示例:
- 使用 GitLab 16.0 起所需的新配置结构。
- 忽略五种常见的检查失败。
Gitaly 文档有更多详细信息 关于其他 Git 检查失败和早期 GitLab 版本。
gitaly['configuration'] = {
git: {
config: [
{ key: "fsck.duplicateEntries", value: "ignore" },
{ key: "fsck.badFilemode", value: "ignore" },
{ key: "fsck.missingEmail", value: "ignore" },
{ key: "fsck.badEmail", value: "ignore" },
{ key: "fsck.hasDotgit", value: "ignore" },
{ key: "fetch.fsck.duplicateEntries", value: "ignore" },
{ key: "fetch.fsck.badFilemode", value: "ignore" },
{ key: "fetch.fsck.missingEmail", value: "ignore" },
{ key: "fetch.fsck.badEmail", value: "ignore" },
{ key: "fetch.fsck.hasDotgit", value: "ignore" },
{ key: "receive.fsck.duplicateEntries", value: "ignore" },
{ key: "receive.fsck.badFilemode", value: "ignore" },
{ key: "receive.fsck.missingEmail", value: "ignore" },
{ key: "receive.fsck.badEmail", value: "ignore" },
{ key: "receive.fsck.hasDotgit", value: "ignore" },
],
},
}GitLab 16.1 及更高版本包含增强功能,可能会解决其中一些问题。
Gitaly 问题 5625 建议确保 Geo 即使源仓库包含有问题的提交也复制仓库。
相关错误 似乎不是一个 git 仓库
您也可能收到错误消息 同步失败 - 同步仓库错误 以及以下日志消息。此错误表示在次要 Geo 站点文件系统上的仓库的 .git/config 文件中不存在预期的 Geo 远程:
{
"created": "@1603481145.084348757",
"description": "Error received from peer unix:/var/opt/gitlab/gitaly/gitaly.socket",
…
"grpc_message": "exit status 128",
"grpc_status": 13
}
{ …
"grpc.request.fullMethod": "/gitaly.RemoteService/FindRemoteRootRef",
"grpc.request.glProjectPath": "<namespace>/<project>",
…
"level": "error",
"msg": "fatal: 'geo' 似乎不是一个 git 仓库
fatal: 无法从远程仓库读取。……",
}要解决此问题:
-
登录次要 Geo 站点的 Web 界面。
-
备份
.git文件夹。 -
可选。抽查 一些 ID 是否确实对应于已知 Geo 复制失败的项目。 使用
fatal: 'geo'作为grep术语和以下 API 调用:curl --request GET --header "PRIVATE-TOKEN: <your_access_token>" "https://gitlab.example.com/api/v4/projects/<first_failed_geo_sync_ID>" -
进入 Rails 控制台 并运行:
failed_project_registries = Geo::ProjectRepositoryRegistry.failed if failed_project_registries.any? puts "Found #{failed_project_registries.count} failed project repository registry entries:" failed_project_registries.each do |registry| puts "ID: #{registry.id}, Project ID: #{registry.project_id}, Last Sync Failure: '#{registry.last_sync_failure}'" end else puts "No failed project repository registry entries found." end -
运行以下命令为每个项目执行新的同步:
failed_project_registries.each do |registry| registry.replicator.sync puts "Sync initiated for registry ID: #{registry.id}, Project ID: #{registry.project_id}" end
回填期间的失败
在回填期间,失败被安排在回填队列末尾重试,因此这些失败仅在回填完成后才会清除。
消息:读取边带数据包时意外断开连接
不稳定的网络条件可能导致 Gitaly 在尝试从主站点获取大型仓库数据时失败。这些条件可能导致此错误:
curl 18 传输关闭,仍有未读取的数据剩余 & fetch-pack:
读取边带数据包时意外断开连接如果仓库必须在站点之间从头复制,则此错误更有可能发生。
Geo 会重试几次,但如果传输因网络故障而持续中断,可以使用 rsync 等替代方法来绕过 git 并创建任何无法通过 Geo 复制的仓库的初始副本。
我们建议单独传输每个失败的仓库,并在每次传输后检查一致性。按照单目标 rsync 说明将每个受影响的仓库从主站点传输到次要站点。
在 Geo 次要站点中查找仓库检查失败
所有仓库数据类型已在 GitLab 16.3 中迁移到 Geo 自助服务框架。有一个问题要在 Geo 自助服务框架中重新实现此功能。
对于 GitLab 16.2 及更早版本:
当为所有项目启用时,仓库检查也会在 Geo 次要站点上执行。元数据存储在 Geo 跟踪数据库中。
Geo 次要站点上的仓库检查失败不一定意味着复制问题。以下是解决这些失败的一般方法。
- 如下所述查找受影响的仓库,以及它们的记录错误。
- 尝试诊断特定的
git fsck错误。可能的错误范围很广,尝试将它们放入搜索引擎。 - 测试受影响仓库的典型功能。从次要站点拉取,查看文件。
- 检查主站点的仓库副本是否具有相同的
git fsck错误。如果您计划故障转移,请考虑次要站点具有与主站点相同的信息。确保您有主站点的备份,并遵循计划故障转移指南。 - 推送到主站点并检查更改是否复制到次要站点。
- 如果复制未自动工作,尝试手动同步仓库。
启动 Rails 控制台会话 以执行以下基本故障排除步骤。
如果未在正确条件下运行,更改数据的命令可能会造成损坏。始终先在测试环境中运行命令,并准备好备份实例以进行恢复。
获取仓库检查失败的仓库数量
Geo::ProjectRegistry.where(last_repository_check_failed: true).count查找仓库检查失败的仓库
Geo::ProjectRegistry.where(last_repository_check_failed: true)重置 Geo 次要站点复制
如果您让次要站点处于损坏状态并想要重置复制状态, 从头开始,有几个步骤可以帮助您:
-
停止 Sidekiq 和 Geo 日志光标。
可以让 Sidekiq 优雅地停止,但让它停止获取新作业并 等待当前作业完成处理。
您需要发送 SIGTSTP 终止信号用于第一阶段,然后发送 SIGTERM 当所有作业完成时。否则只需使用
gitlab-ctl stop命令。gitlab-ctl status sidekiq # run: sidekiq: (pid 10180) <- 这是您将使用的 PID kill -TSTP 10180 # 更改为正确的 PID gitlab-ctl stop sidekiq gitlab-ctl stop geo-logcursor您可以观看 Sidekiq 日志 来了解 Sidekiq 作业处理何时完成:
gitlab-ctl tail sidekiq -
清理 Gitaly 和 Gitaly 集群(Praefect)数据。
mv /var/opt/gitlab/git-data/repositories /var/opt/gitlab/git-data/repositories.old sudo gitlab-ctl reconfigure-
可选。禁用 Praefect 内部负载均衡器。
-
在每个 Praefect 服务器上停止 Praefect:
sudo gitlab-ctl stop praefect -
重置 Praefect 数据库:
sudo /opt/gitlab/embedded/bin/psql -U praefect -d template1 -h localhost -c "DROP DATABASE praefect_production WITH (FORCE);" sudo /opt/gitlab/embedded/bin/psql -U praefect -d template1 -h localhost -c "CREATE DATABASE praefect_production WITH OWNER=praefect ENCODING=UTF8;" -
从每个 Gitaly 节点重命名/删除仓库数据:
sudo mv /var/opt/gitlab/git-data/repositories /var/opt/gitlab/git-data/repositories.old sudo gitlab-ctl reconfigure -
在您的 Praefect 部署节点上运行 reconfigure 来设置数据库:
sudo gitlab-ctl reconfigure -
在每个 Praefect 服务器上启动 Praefect:
sudo gitlab-ctl start praefect -
可选。如果您禁用了它,请重新激活 Praefect 内部负载均衡器。
您可能希望将来删除
/var/opt/gitlab/git-data/repositories.old, 一旦您确认不再需要它,以节省磁盘空间。 -
-
可选。重命名其他数据文件夹并创建新的。
您在次要站点上可能仍有文件已被从主站点删除, 但此删除尚未反映。如果您跳过此步骤,这些文件不会从 Geo 次要站点中删除。
任何上传的内容(如文件附件、头像或 LFS 对象)都存储在这些路径之一的子文件夹中:
/var/opt/gitlab/gitlab-rails/shared/var/opt/gitlab/gitlab-rails/uploads
重命名所有这些:
gitlab-ctl stop mv /var/opt/gitlab/gitlab-rails/shared /var/opt/gitlab/gitlab-rails/shared.old mkdir -p /var/opt/gitlab/gitlab-rails/shared mv /var/opt/gitlab/gitlab-rails/uploads /var/opt/gitlab/gitlab-rails/uploads.old mkdir -p /var/opt/gitlab/gitlab-rails/uploads gitlab-ctl start postgresql gitlab-ctl start geo-postgresql重新配置以重新创建文件夹并确保权限和所有权 正确:
gitlab-ctl reconfigure -
重置跟踪数据库。
如果您跳过了可选步骤 3,请确保
geo-postgresql和postgresql服务都在运行。gitlab-rake db:drop:geo DISABLE_DATABASE_ENVIRONMENT_CHECK=1 # 在次要应用节点上 gitlab-ctl reconfigure # 在跟踪数据库节点上 gitlab-rake db:migrate:geo # 在次要应用节点上 -
重新启动之前停止的服务。
gitlab-ctl start